
Abstract
Image pretrained MLLM을 비디오에 간단하고 효과적으로 적용하기 위한 방법 조사
[Github]
[arXiv](2024/04/25 version v1)
Method & Analysis
Failure Cases Analysis for Applying Image MLLMs
사전 훈련된 인코더를 통해 비디오의 각 프레임을 인코딩하고 LLM에 입력하는 n-frame 시나리오에서 문제 분석.
Vulnerability to prompts
OOD(out-of-distribution) prompt를 사용하면 답변의 품질이 급격하게 저하된다.
반면 PLLaVA는 일관된 길이의 답변을 출력한다.

Dominant tokens
히스토그램은 모델 전반에 걸친 vision token들의 norm을 시각화한 것인데, n-frame에서 일부 지배적인 토큰의 출현을 볼 수 있다.
Data scaling failures
n-frame은 데이터를 확장해도 성능이 정체된다.

Model Scaling Degradation
현재 비디오 모델에 대한 조사에 따르면 모델 크기를 늘려도 성능이 비례적으로 증가하지 않는다.

PLLaVA

Vision encoder, projector, LLM은 MLLM의 일반적인 구조이다.
PLLaVA는 여기서 풀링을 통해 feature를 한번 더 압축하고 LoRA로 LLM을 fine-tuning 한다.
Post Optimization
위에서 언급했듯이 PLLaVA 또한 모델 크기와 성능이 비례하지 않는다. 연구진은 성능 저하의 이유가 낮은 품질의 비디오-텍스트 데이터 학습으로 인한 언어 능력 저하 때문이라고 가정했다.
훈련 후 최적화의 일환으로 LoRA의 영향력을 조절하여 원본 image MLLM과 가중치를 혼합하는 것과 같은 효과를 낸다.
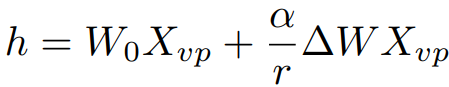
Experiments
Baseline: LLaVA-NeXT
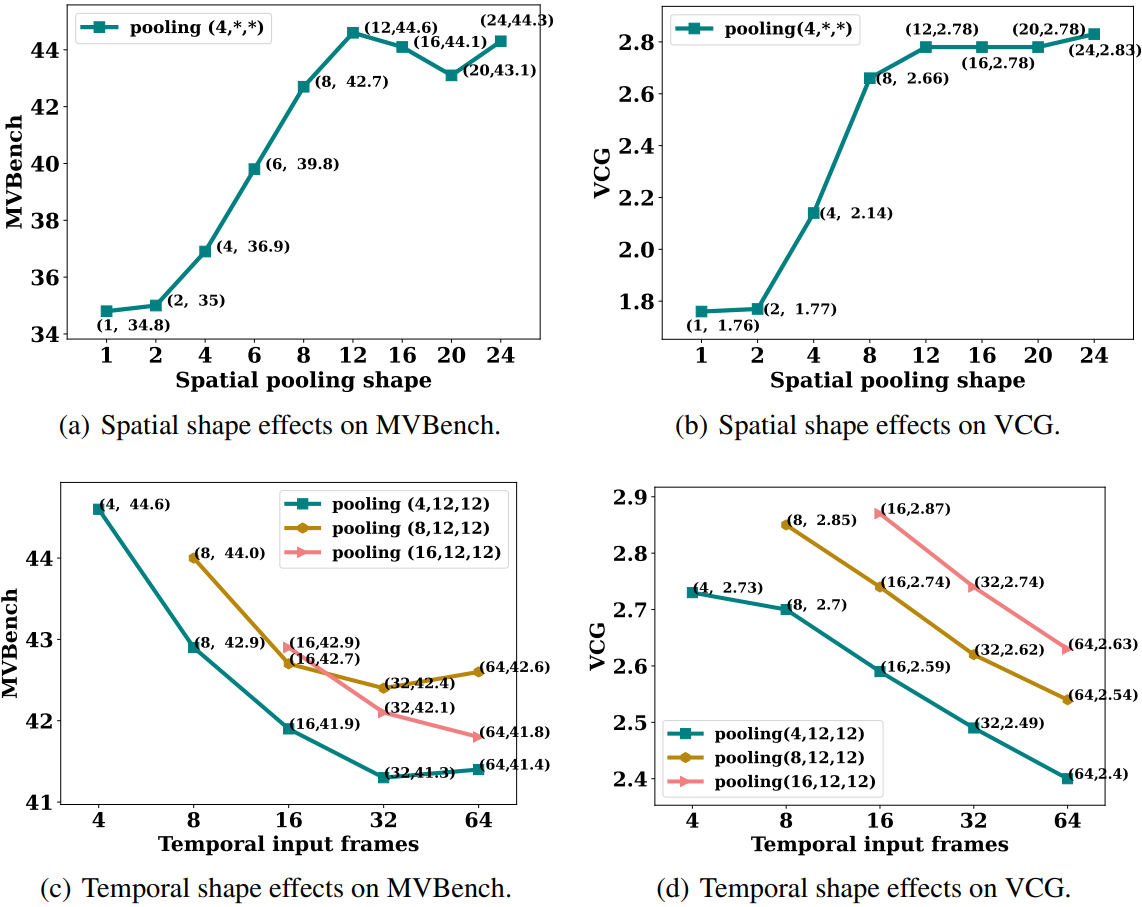
풀링 모양에 따른 성능
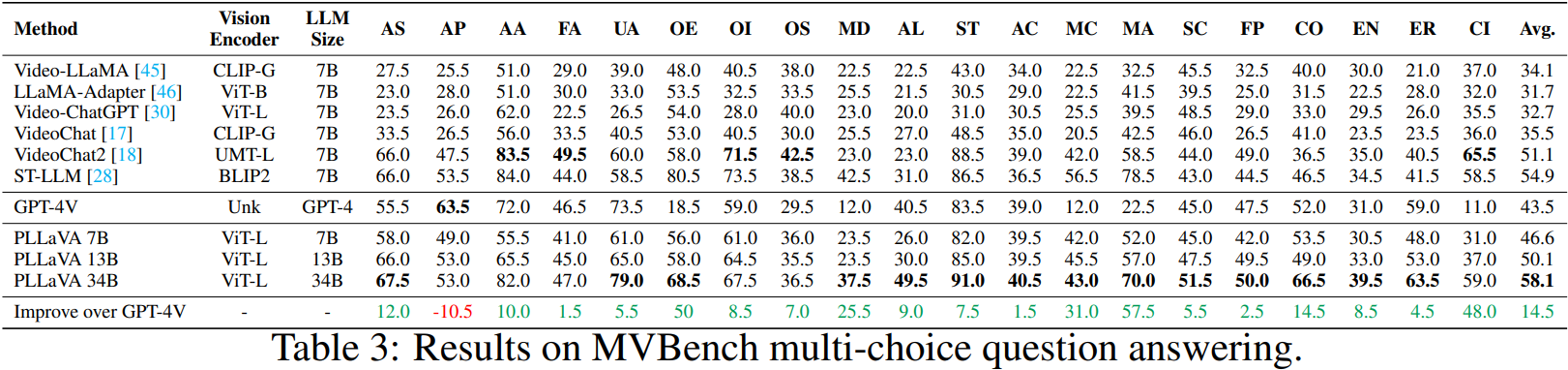
정량적 평가

PLLaVA: Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
▶ A Simple Video demonstrating the application.
pllava.github.io



