
PoLL이 인간 판단과의 상관관계 (Kappa Score)가 가장 높다.
Abstract
Panel of LLM evaluators (PoLL)을 구성하여 LLM의 품질을 평가
[arXiv](2024/04/29 version v1)
Introduction
최근 GPT-4와 같은 LLM을 평가자로 사용하는 것이 일반화되고 있지만 단일 모델에는 고유한 편견이 있다.
Methods
Background: LLM as a Judge
판사 모델 J가 출력 모델 A의 출력 a를 평가하는 데 사용된다.
Single-point Scoring
score = J(a)
Reference-based Scoring
판사 모델에 gold reference r이 제공된다.
score = J(a, r)
Pair-wise Scoring
두 모델A, B의 출력 a, b를 비교한다.
score = J(a, b)
Panel of LLM Evaluators
각 판사 모델이 독립적으로 점수를 매긴 후 집계한다.
Experimental Settings
PoLL에는 Command R, GPT-3.5, Claude-3 Haiku가 포함된다.
또한 비교를 위해 Chatbot Arena의 leaderboard, 인간의 판단, 응답 내에 참조 답변 문자열이 나타나는지 확인하는 exact match (EM) metric을 사용한다.
Results
Cohen’s kappa로 측정한 인간 판단과의 유사성:
Chatbot Arena 순위와 비교:
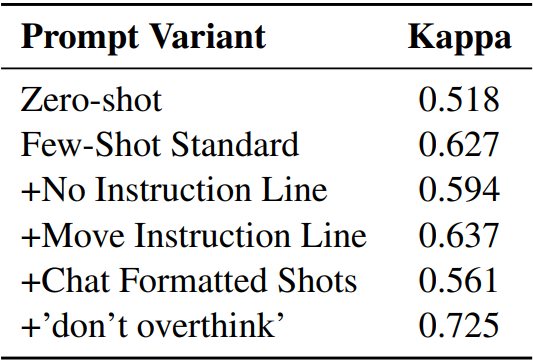
판사 모델로써 GPT-4의 성능이 좋지 않은 이유 중 하나는 너무 지나치게 추론하기 때문이다.
Prompt를 변경함으로써 성능을 향상시킬 수 있지만 여전히 PoLL보다 낮다.
평가의 일관성: 각 모델에 대한 평가가 인간의 판단과 얼마나 벗어나는지 측정
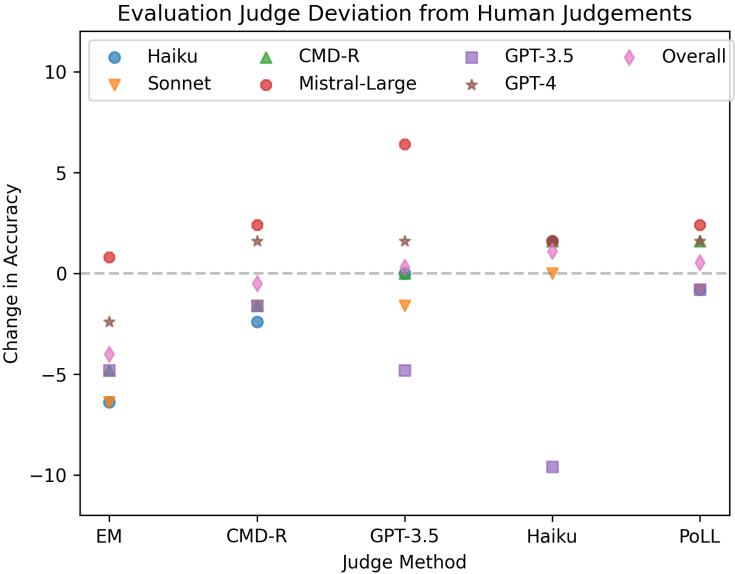 HotPotQA |
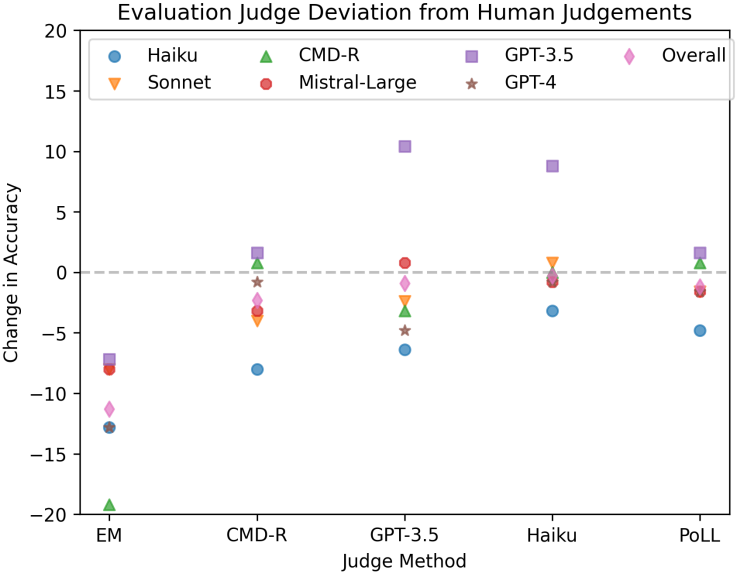 |



