Abstract
Multi-token prediction training을 하면 single-head에서도 성능이 향상된다?
[arXiv](2024/04/30 version v1)
Parallel decoding, speculative decoding에 대한 논문은 많지만 이 논문의 신기한 점은 훈련은 multi-head로 하면서 추론은 single-head로 한다는 점이다.
그러니까 추론 시에는 일반적인 LLM과 똑같은데 코딩 작업에서 성능이 향상되었다.
아마 코딩 작업은 어느 정도 정답이 정해져 있기에 그런 듯?
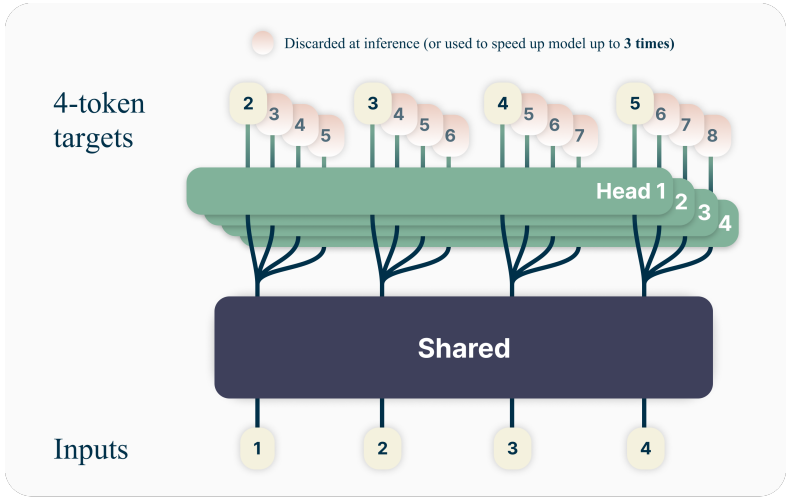
Method
Shared trunk의 출력에서 각각 다른 head를 통해 미래 n개의 토큰을 동시에 예측한다.
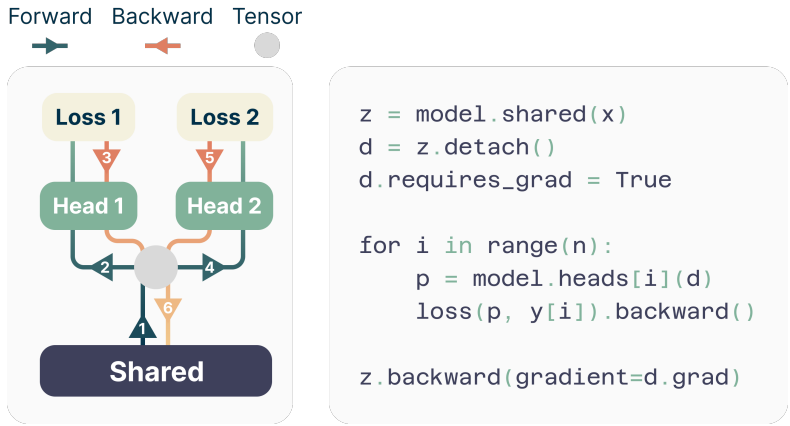
Memory-efficient implementation
각 head의 gradient를 trunk에 누적하고 해제하여 head 수가 늘어나도 메모리 부담이 늘지 않도록 하였다.
Inference
Medusa와 같이 병렬 헤드를 통해 speculative decoding을 할 수도 있지만 기본적인 용도는 다른 헤드를 버리고 다음 토큰 예측 헤드만 사용하는 것이다.
Experiments on real data
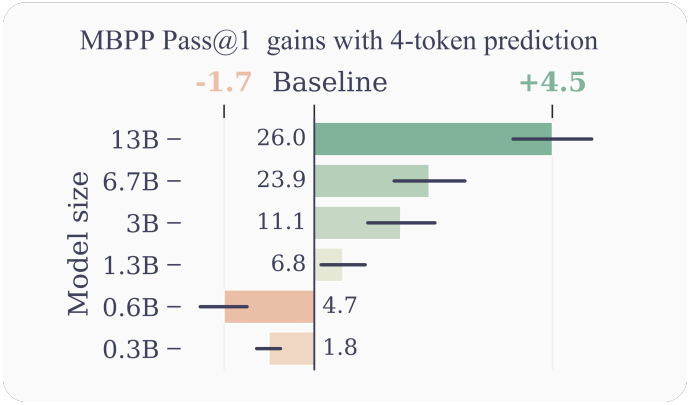
요약: 코딩 작업에는 강세를 보이는데 다른 작업은 그닥인듯...?
모델 크기가 클수록 multi-head training의 수혜를 받는다. (검은 막대는 90% 신뢰구간)

4~8 heads가 보통 최적이다. @n은 training epochs

자연어는 후달림.

수학도 그닥...?




