Abstract
CoT를 DPO에 사용하여 모델을 반복적으로 개선하는 Iterative RPO 제안
[arXiv](2024/04/30 version v1)
Iterative Reasoning Preference Optimization

CoT와 답변을 생성하고 순위를 매기고
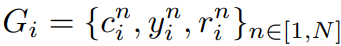
DPO + NLL의 조합으로
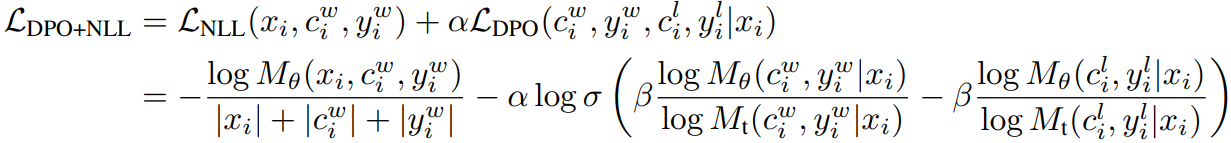
반복적으로 개선한다.

Experiments

CoT를 DPO에 사용하여 모델을 반복적으로 개선하는 Iterative RPO 제안
[arXiv](2024/04/30 version v1)
CoT와 답변을 생성하고 순위를 매기고
DPO + NLL의 조합으로
반복적으로 개선한다.



