Abstract
직접 평가 및 쌍별 순위 지정을 모두 수행할 수 있고 이전 버전보다 향상된 evaluator LM인 Prometheus 2 소개
[Github]
[arXiv](2024/05/02 version v1)
Introduction
LM의 품질을 평가하기 위해 독점 LM에 의존하는 것은 문제를 야기한다.
투명하고 제어 가능하고 인간과의 일치도가 가장 높으며 직접 평가와 쌍별 순위를 매길 수 있는 통합 평가 모델 개발.
Methodology
i) Direct Assessment
직접 평가는 지시와 그에 대한 응답을 스칼라 점수로 매핑하는 것이다.
인간 평가와의 상관관계를 최대화하기 위한 최근의 연구들을 반영하면,
모델에 참조 답안 a와 평가 기준 e를 제공하고 추가적으로 피드백 v를 출력하도록 한다.
ii) Pairwise Ranking
쌍별 순위는 지시에 대한 두 응답 중 하나를 선택하는 평가 방식이다.
변형:
iii) The Preference Collection
Preference Collection을 구축하기 위해 Feedback Collection dataset에 2가지 수정을 적용해 쌍별 순위 데이터로 만듦.
- Feedback collection에는 각 지시문마다 1~5점에 해당하는 5개의 응답이 있다. 2개의 응답을 페어링하여 총 10개의 조합을 만들고 더 나은 응답을 식별한다.
- 쌍별 순위에 대한 피드백을 생성하기 위해 GPT-4를 통해 두 응답의 공통점과 차이점을 식별하도록 프롬프트했다.
iv) Employing Evaluator Language Models
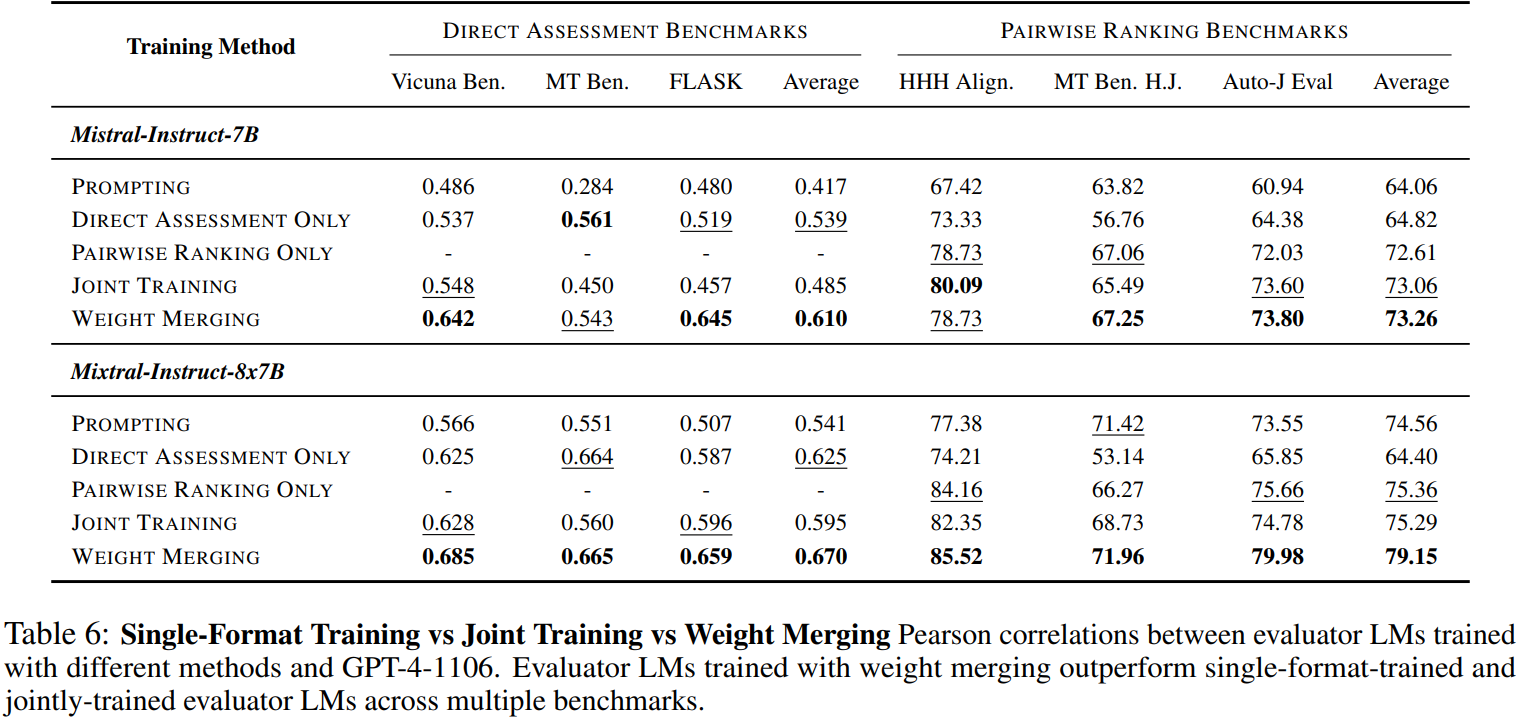
직접 평가, 쌍별 순위 데이터에 대해 각각 훈련하고 가중치를 병합한다.
Linear merging
Mistral-7B에서 가장 잘 작동했다.
DARE merging
Drop And Re-scale의 약자다. 말 그대로다.
Mixtral-8×7B에서 가장 잘 작동했다.
Experimental Results
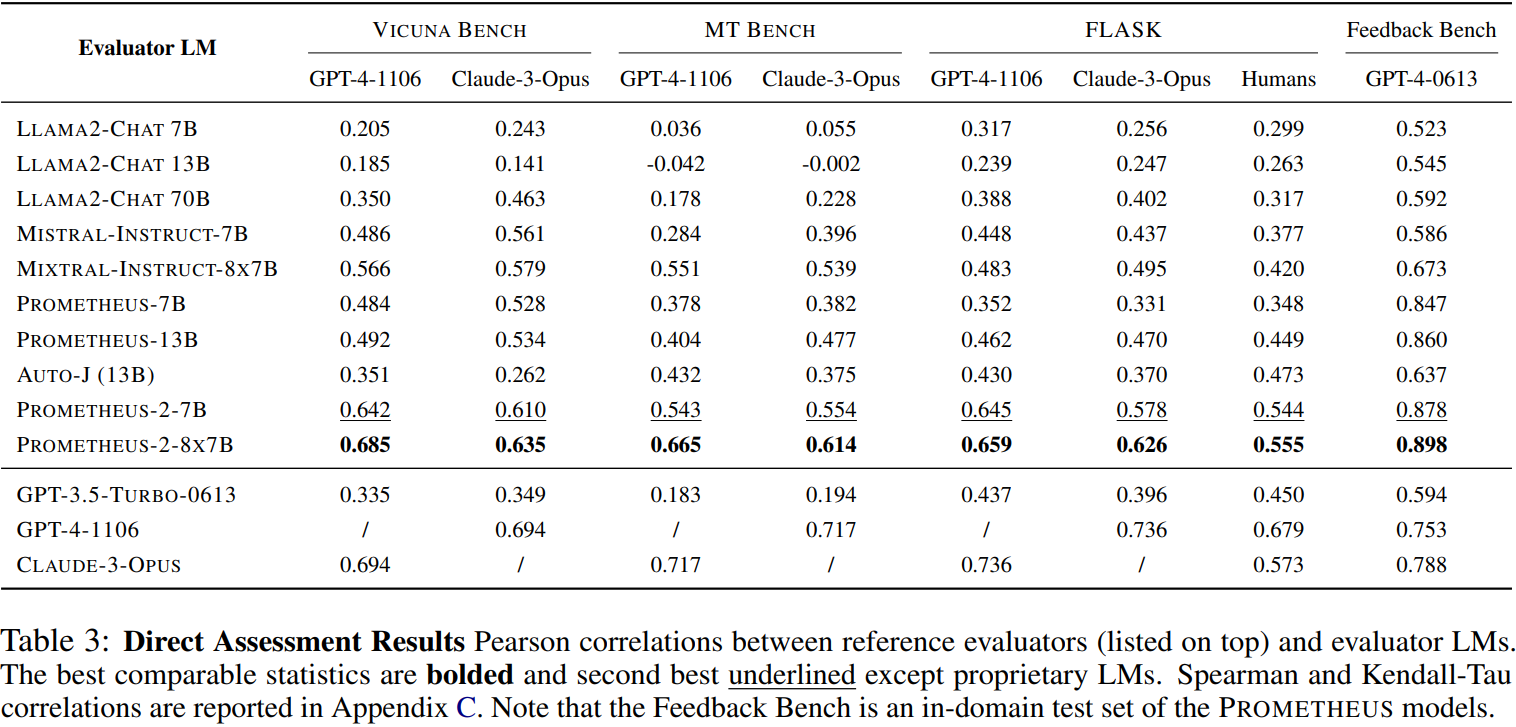
직접 평가
쌍별 순위

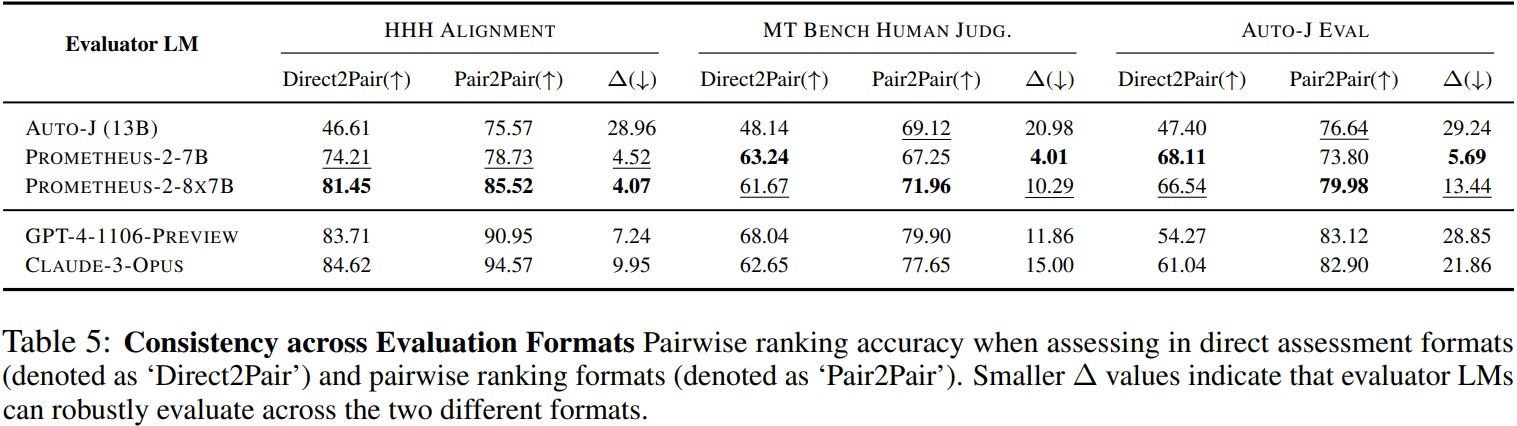
평가에 대한 일관성
모델 병합의 효과:
병합 모델 > 단일 모델 > 공동 훈련 모델
병합 모델은 직접 평가, 쌍별 순위에서 단일 모델보다 성능이 좋았다.