Abstract
Autoregression을 위해 설계된 완전히 미분 가능한 MoE 아키텍처인 Lory 소개
[arXiv](2024/05/06 version v1)
Preliminaries
Mixture-of-Experts (왼쪽): 라우터가 입력 토큰에 적절한 특정 전문가를 선택한다.
SMEAR (오른쪽): 라우팅 결과의 가중 평균을 통해 단일 전문가로 병합하여 토큰을 처리한다. 모든 구성요소가 미분 가능하여 보조 손실 없이 end-to-end 훈련이 가능하다.
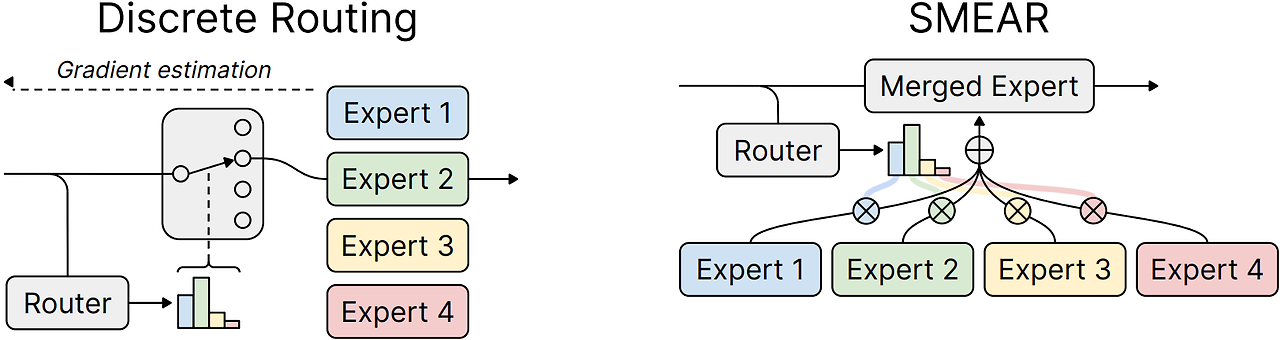

하지만 이 방법은 전문가의 수가 커짐에 따라 계산 비용이 증가하므로 실현 불가능하다.
Lory
표기: 토큰 집합 X로 이루어진 시퀀스 L을 크기가 T인 N개의 segment로 나누고 각 segment를 Si, routing network를 R, hidden representation h, 각 전문가 피라미터 θi로 표기한다.

Efficient Expert Merging via Causal Segment Routing
Token-level이 아닌 segment-level routing을 수행한다.
구체적으로, 이전 segment에 속한 토큰들의 라우팅 결과를 집계하여 FFN을 병합한 다음 그 FFN을 다음 segment의 출력을 계산하는 데 사용한다.

토큰마다 일일이 다른 비율로 전문가를 병합할 필요가 없어 계산 오버헤드가 크게 절약된다.
Prompt-only routing during inference
추론 시에는 user prompt를 통해 병합 FFN을 생성하고 이를 전체 생성 과정에 사용하여 더욱 효율적인 추론이 가능하다.
Similarity-based Data Batching
일반적으로 LM을 훈련할 때 문서들을 무작위로 연결하여 고정 길이의 훈련 인스턴스를 생성한다. 하지만 연결된 문서 간의 연관성이 전혀 없을 수도 있으며 그럴 경우 전문가의 전문성 부족이 문제가 될 수 있다.
대신 Contriever를 통해 문서 간의 유사도를 측정하고 유사한 문서들을 연결하여 인접한 segment들이 유사한 내용을 공유할 수 있도록 한다.
Experiments
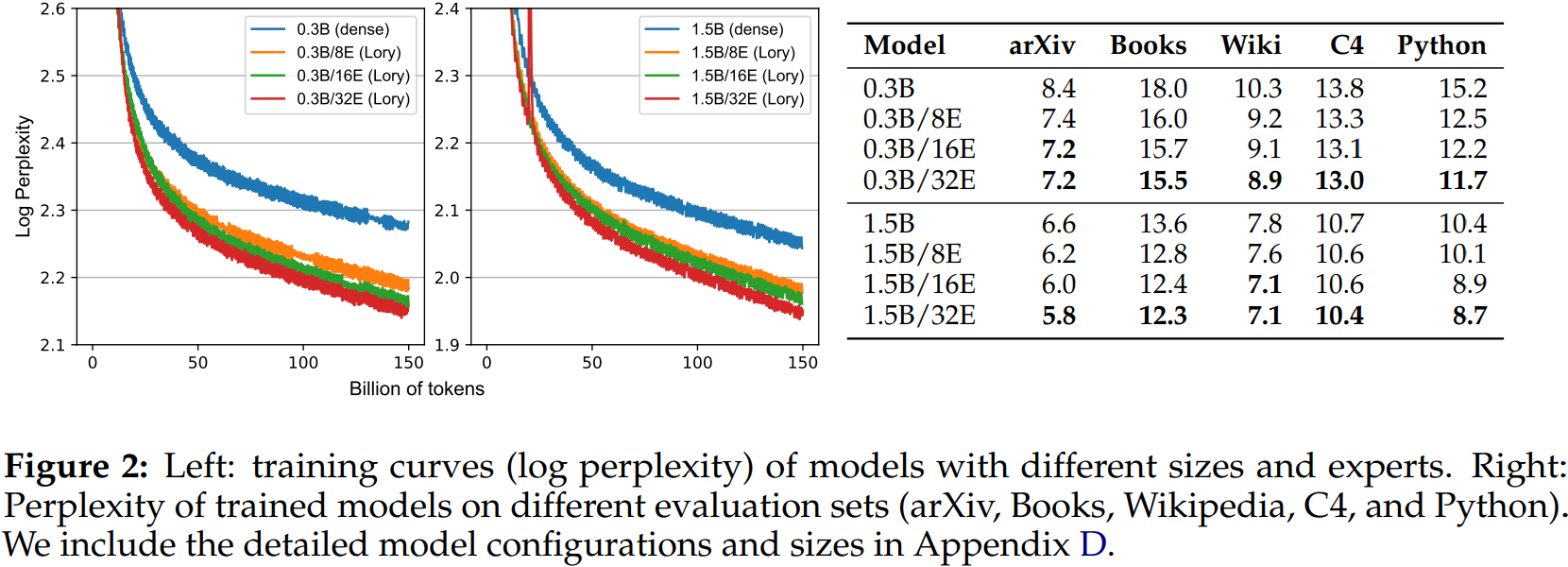
Perplexity
Downstream task




