Abstract
VLM의 구성에 대한 광범위한 실험을 수행하고 결과를 기반으로 foundational VLM인 Idefics2 개발
[arXiv](2024/05/03 version v1)
Exploring the design space of vision-language models
Finding 1. Vision backbone의 품질보다 Language backbone의 품질이 더 중요하다.
|
|
Finding 2. Unimodal backbone이 고정된 상태일 때 cross-attention의 성능이, 그렇지 않은 경우 fully-autoregressive의 성능이 더 좋다.
Finding 3. Fully-autoregressive architecture를 unfreezing 하면 훈련 발산이 발생할 수 있지만 LoRA를 사용하면 괜찮다.
Cross-attention architecture의 경우 1.3B의 추가 피라미터와 10%의 추가 flops가 필요한데도 말이다.
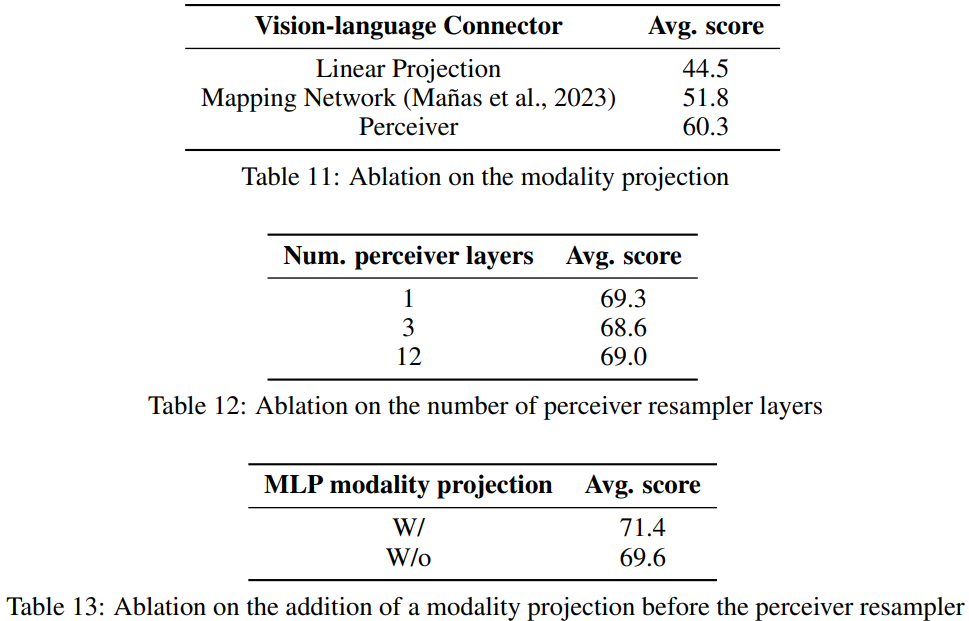
Finding 4. Visual token의 수를 줄이면 컴퓨팅 효율성과 downstream 성능이 향상된다.
구체적으로 transformer 기반의 perceiver를 사용하여 visual sequence 길이를 줄인다.
Finding 5. 정사각형 이미지에서 훈련된 vision backbone에 맞추기 위해 직사각형 이미지의 종횡비를 변경하지 않고 특정 방법을 사용하면 더 성능이 좋다.
Finding 6. 입력 이미지를 하위 이미지로 분할하면 downstream 성능이 향상된다.
하지만 이 방법은 visual token의 수가 늘어나 훈련이 비효율적으로 된다.
따라서 instruction fine-tuning 단계에서만 사용하고, 추가로 이미지의 50%에만 적용하면 성능이 저하되지 않으면서 이점을 누릴 수 있다고 한다.
Idefics2 - an open state-of-the-art vision-language foundation model
Multi-stage pre-training
Interleaved image-text documents, Image-text pairs, PDF documents에 대해 pre-training 수행.
텍스트 추출 능력을 향상시키기 위해 PDF를 포함하였다.
훈련은 2개의 단계로 진행되며 1-stage에서는 저해상도 대규모 훈련, 2-stage에서는 PDF를 포함하여 고해상도에서 훈련한다.
사전 훈련 모델의 성능:

Instruction fine-tuning
다양한 vision-language task collection인 The Cauldron을 출시하고 최종 훈련 데이터에는 only-text 데이터를 추가한다.
훈련 중 과적합을 피하기 위해 이미지의 해상도를 무작위로 확장하고, 임베딩에 노이즈를 추가하고, LoRA의 변형인 DoRA를 사용한다.
Instruction tuning 성능:

추가적으로 채팅 시나리오에 대해 훈련하여 Idefics2-chatty 출시.
Ablation