Abstract
새로운 사실적 지식을 학습하는 것이 LLM에 미치는 영향을 조사
[arXiv](2024/05/13 version v2)
Quantifying Knowledge in LLMs
새로운 지식이 포함된 fine-tuning dataset D가 모델의 성능에 미치는 영향을 평가하기 위해 주로 사실적 지식으로 구성된 D의 다양한 변형을 생성한다.
D는 Wikidata의 삼중항(주제, 관계, 객체)을 QA 형식으로 변환하여 구성된다.
E.g. '음바페는 PSG 소속이다.' → ('음바페는 어느 팀 소속인가요?', 'PSG')
질문에 대한 올바른 답변을 알고 있을 확률인 PCorrect를 측정하고 이를 통해 지식을 분류한다.
이른바 SliCK(Sampling-based Categorization of Knowledge):

How Harmful are Unknown Examples?
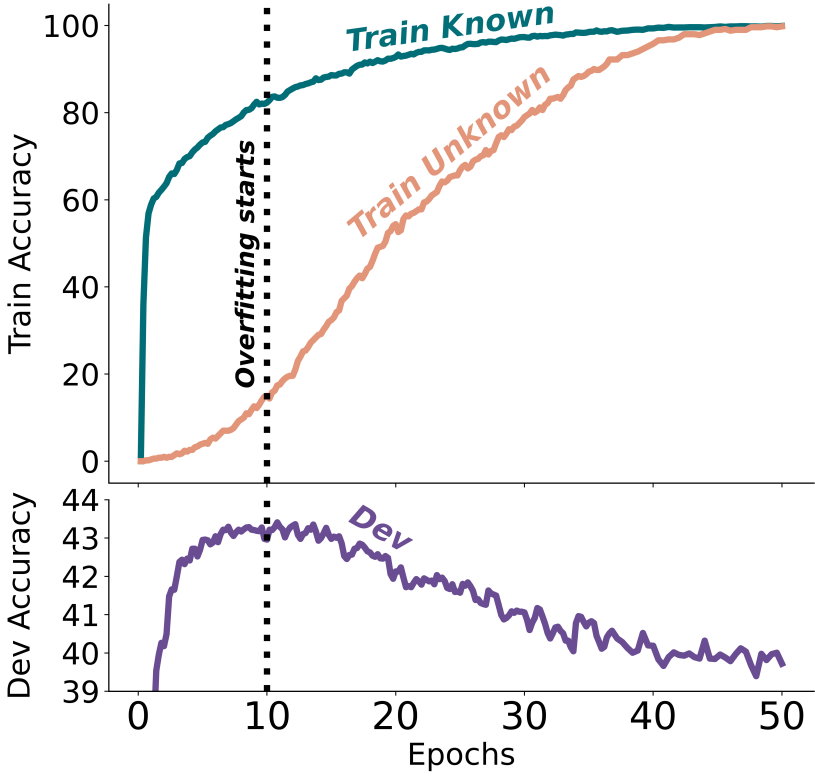
(a) Unknown data가 많이 포함될수록 fine-tuning 성능이 저하되었다. 또한 Fine-tuning을 너무 많이 하면 D에 과적합되어 성능이 저하되었다.
(b) Unknown을 제거한 D(점선)에서 훈련한 경우 조기 중지 모델과 수렴 모델이 거의 차이가 없는 것으로 보아 unknown data가 성능 저하를 유발하는 것으로 볼 수 있다. 또한 조기 중지한 경우 unknown data의 영향이 거의 없다.

Unknown data는 느리게 학습된다. 이 때문에 조기 중지 모델에서 영향이 없는 것이다.
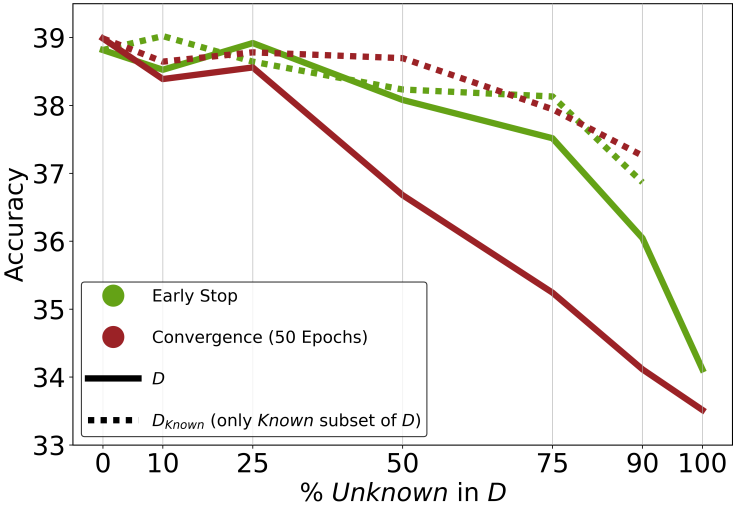
D에 unknown data가 많을수록 모델이 기존 지식에 기반하지 않은 답변을 생성하는 방법을 학습하여 out-of-distribution 성능이 저하된다.
Understanding Knowledge Types: Their Value and Impact
아래 표에서 Ddata는 data 범주로만 구성된 데이터셋을 나타내며, natural은 자연적인 범주 분포를 말한다. 크기는 모두 같다.
Ddata로 fine-tuning 후 각 범주에 대한 성능을 비교한 것이다.
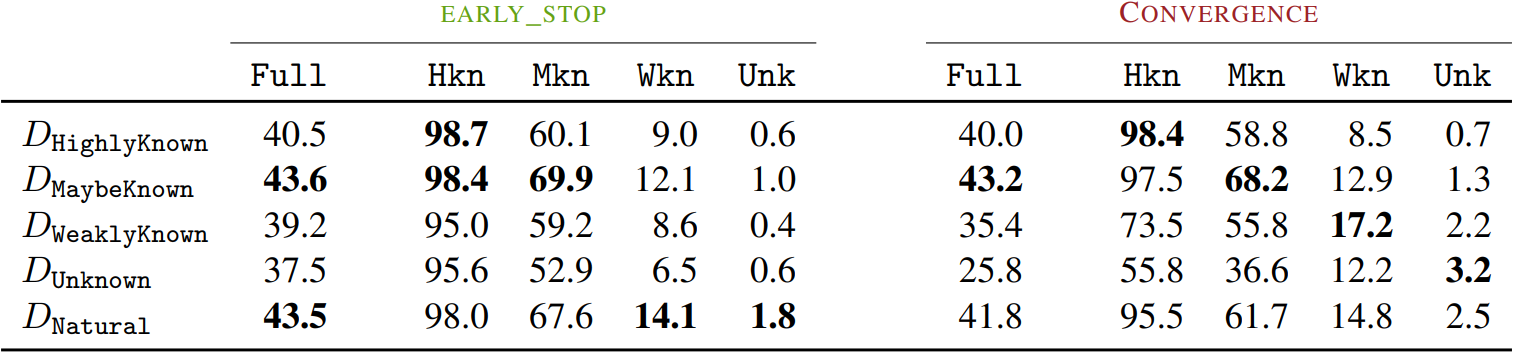
- MaybeKnown data가 MK의 성능을 향상하면서 다른 범주에 대한 정확도를 잘 유지하여 가장 필수적이었다. (HK는 이미 완전히 알고 있는 것이라 별로 영향이 없고, MK의 부족한 지식을 보충해주면서 성능이 향상되는 느낌.)
- 수렴 모델의 성능 저하를 보면 WK 또한 UK 보다는 덜하지만 환각 문제를 일으키는 것으로 보인다.
- 신기한 점은 자연 분포 데이터셋보다 MK 단일 범주에서 fine-tuning 했을 때 성능이 더 좋았다는 것이다. WK와 UK로 인한 환각 때문에 HK, MK의 성능이 떨어진 것으로 보인다.



