Abstract
최신 LLM 기술을 활용하여 LSTM을 수십억 피라미터로 확장
[arXiv](2024/05/07 version v1)
Introduction
RNN의 일종으로 forget gate를 통해 이전 셀의 정보를 얼마나 잊을지, input gate를 통해 새로운 정보를 얼마나 반영할지, output gate를 통해 출력을 제어한다.

Extended Long Short-Term Memory
Review of the Long Short-Term Memory
sLSTM
LSTM이 정보를 더 잘 조절할 수 있게 하기 위해 값을 0~1로 제한하는 sigmoid gate 대신 지수 게이트를 도입하고 안정화를 위해 normalizer state를 추가한다.
지수 함수의 큰 값은 overflow를 일으킬 수 있기 때문에 stabilizer state를 추가하여 safe softmax를 사용한다.
New Memory Mixing
Attention heads와 비슷하게 입력의 차원을 각 head로 나누어 각각 별개의 memory cell을 통과하고 혼합한다.
mLSTM
LSTM의 저장 능력 향상을 위해 스칼라 c 대신 행렬 C를 사용한다.
Transformer에서 query, key, value의 개념을 가져왔다.
다음과 같이 k와 v의 외적을 쌓는 형태로 C를 업데이트하면,
이후 timestep에서 q와 C의 곱으로 이전 timestep의 v를 검색할 수 있다고 한다.
Forget gate와 input gate는 이전 값을 얼마나 잊을지, 새로운 값을 얼마나 반영할지를 결정하며 output gate는 검색된 벡터를 스케일링하는 역할을 한다.
mLSTM도 마찬가지로 safe softmax를 사용하고 여러 개의 memory cell을 가지지만 병렬화를 통한 연산 효율성을 확보하기 위해 memory mixing을 포기하였다. (memory mixing 수행 시 memory cell이 서로 연관되기 때문에 병렬 연산이 불가능하다.)
xLSTM Architecture
2가지 블록 형태를 고려했다.
- Post up-projection: 과거 정보를 비선형적으로 요약한 후 고차원 공간에 매핑한 후 비선형 활성화함수를 적용하고 다시 원래 공간으로 매핑 (e.g. Transformer)
- Pre up-projection: 고차원 공간에서 모두 수행 (e.g. Mamba)
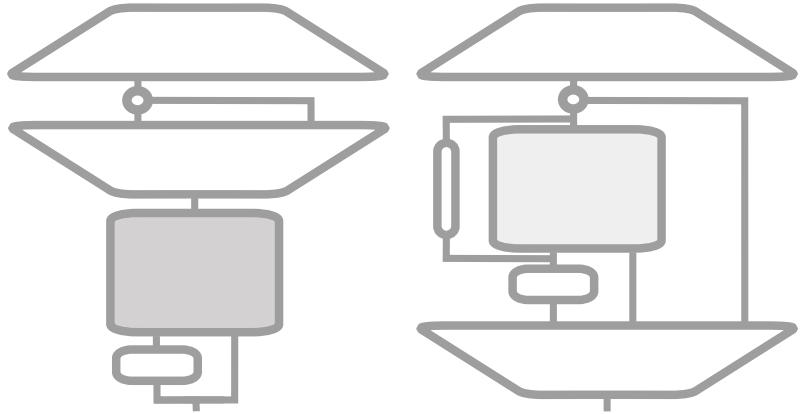
sLSTM이 있는 xLSTM block은 post up-projection을, mLSTM이 있는 block은 pre up-projection을 사용한다.
또한 일반적인 LLM에서 사용되는 잔차 연결, pre-LayerNorm 적용.
Experiments
이걸 보고 전 Google Brain 연구원은 '어차피 규모 커지면 transformer가 다 이김' 이라고 했다.


Next token prediction