Abstract
Octopus v2 + vision : on-device function calling
[arXiv](2024/04/18 version v2)
Methodology
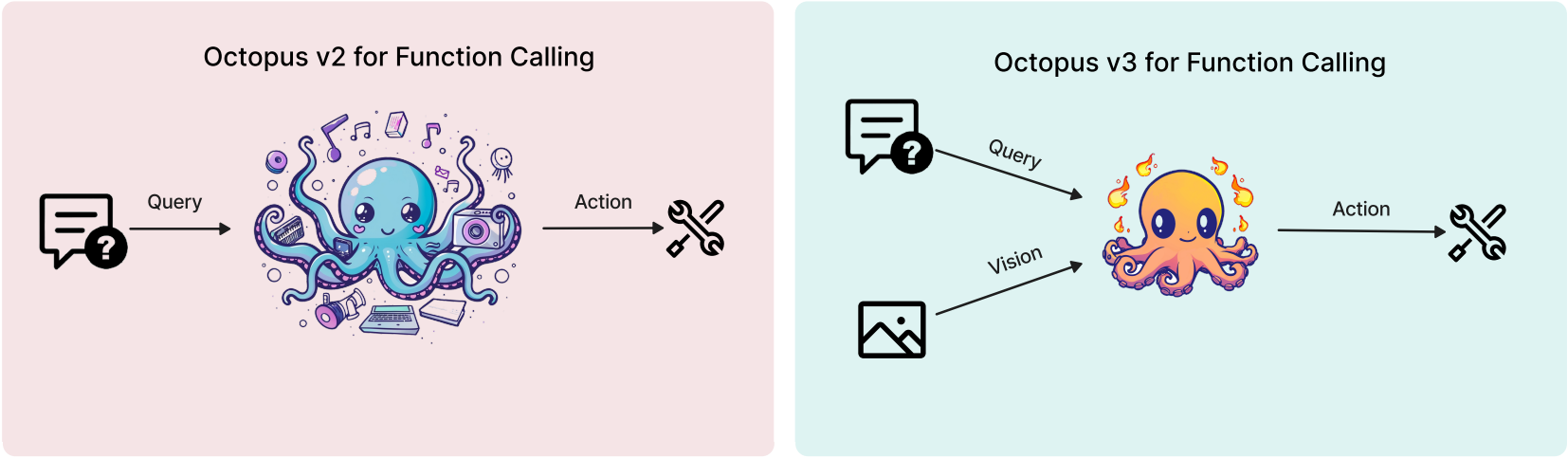
Encoding visual information
CLIP 기반 vision encoder를 사용한다.
Functional token
Octopus v2와 똑같이 functional token을 사용하여 기능을 호출한다.
Multi-stage training
사전 훈련된 vision encoder, LLM의 정렬을 학습 → functional token 학습
Model evaluation
모델의 피라미터 수는 1B 미만이며 아래 결과들은 출력 parser가 필요하지 않은 직접 출력이다.
이메일 보내기

구글 검색하기

아마존 구매

DoorDash (음식 배달 회사)

'논문 리뷰 > Language Model' 카테고리의 다른 글
| Iterative Reasoning Preference Optimization (0) | 2024.05.03 |
|---|---|
| Better & Faster Large Language Models via Multi-token Prediction (2) | 2024.05.03 |
| Octopus v4: Graph of language models (0) | 2024.05.03 |
| Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models (PoLL) (0) | 2024.05.01 |
| PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning (0) | 2024.04.30 |
| FILM: Make Your LLM Fully Utilize the Context (0) | 2024.04.29 |



