

Abstract
두 개의 특정 블록의 LoRA 가중치를 학습하여 암시적으로 content와 style을 분리하는 B-LoRA 제안
[Github]
[arXiv](2024/03/21 version v1)

Method
SDXL Architecture Analysis
SDXL의 각 block에 다른 prompt를 주입하여 영향을 분석했다.
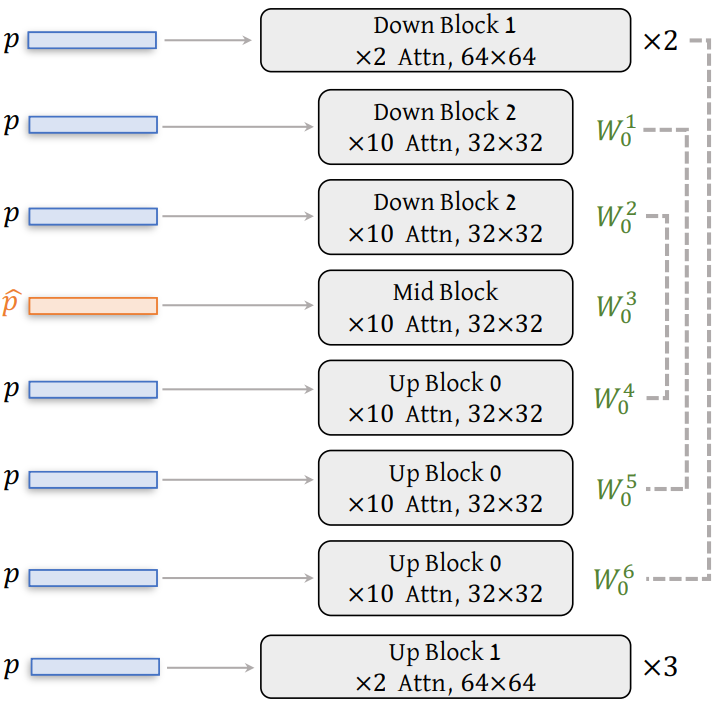
2, 4 block은 content를, 5 block은 색상을 주로 결정하는 것으로 나타났다.

LoRA-Based Separation with B-LoRA
실험 결과 2 block 보다 4 block이 content를 더 잘 보존했다.
직관적으로도 down blocks에서 feature가 압축되므로 up blocks에서 content를 변경하는 것이 맞다.

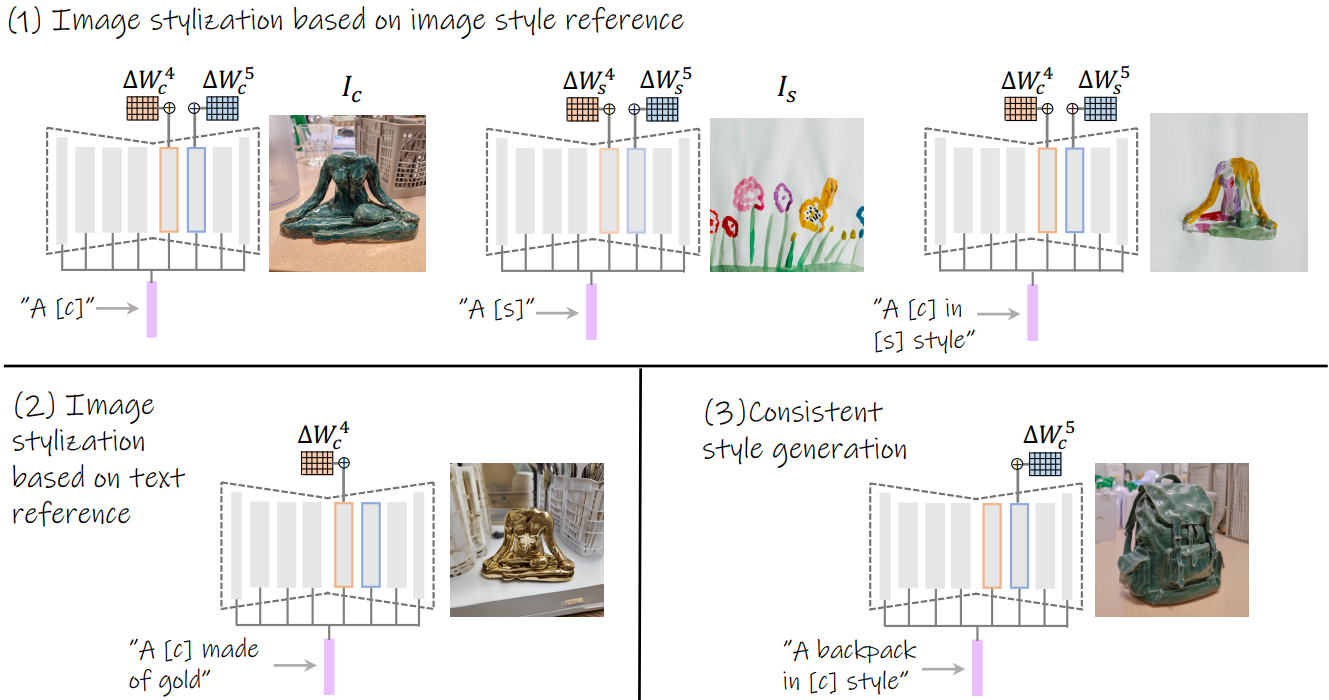
B-LoRA for Image Stylization
주어진 이미지에 대해 "A [v]" 같은 간단한 prompt로 ∆W4 , ∆W5를 훈련한다.
이 두 레이어만 훈련하는 것으로 암시적으로 content와 style이 분리된다.
적당한 prompt와 ∆W4 , ∆W5를 잘 활용하여 content와 style을 조절할 수 있다.
Implementation details
SDXL v1.0
LoRA r = 64
단일 이미지, CenterCrop
보통 LoRA는 과적합 때문에 400 optimizer step 정도를 사용하지만 1000 step 사용
Results
비교

더 많은 결과는 Project Page
Implicit Style-Content Separation using B-LoRA
Image stylization involves manipulating the visual appearance and texture (style) of an image while preserving its underlying objects, structures, and concepts (content). The separation of style and content is essential for manipulating the image's style i
b-lora.github.io
Limitations and Future work

(a): 색상이 스타일에 포함되어 content의 정체성을 유지하지 못할 수 있다.
(b): 단일 이미지를 사용하기 때문에 배경의 스타일이 포함된다.
(c): 복잡한 장면에서 content 보존이 어렵다.
향후 content, style을 넘어서 더 많은 하위 요소로 분리할 수 있으면 좋을 것.



