
Abstract
정확한 text-image 정렬을 가능하게 하는 end-to-end fine-tuning 전략인 CoMat 제안
[Github]
[arXiv](2024/04/04 version v1)
Method
- Concept Matching
- Attribute Concentration
- Fidelity Preservation

Concept Matching
Captioning model이 생성된 이미지를 보고 prompt의 다음 단어를 예측할 확률을 통해 text-image 정렬을 측정.

Attribute Concentration

spaCy를 통해 prompt를 구문 분석하여 명사, 속성 쌍 {n, a}을 수집하고 일부 명사 필터링.(e.g. 추상 명사, 배경을 설명하는 명사, 지역을 식별하기 어려운 명사)
Grounded-SAM을 통해 명사의 마스크를 찾고 n, a, M을 활용하여 attention map을 조정하기 위한 2가지 손실 사용.
Token-level attention loss:
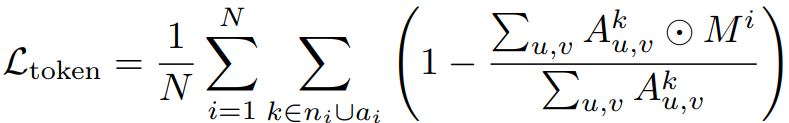
Pixel-level attention loss:

Fidelity Preservation
Overfitting으로 인해 낮은 품질의 이미지가 생성될 수 있다. 이를 완화하기 위해 pretrained model과 fine-tuning model의 출력을 구분하는 판별기 D를 훈련한다.
D의 아키텍처로 U-Net을 사용하고 pretrained model로 초기화하면 빠르게 수렴할 수 있다.

적대적 손실을 통해 G인 fine-tuning model과 D를 동시에 훈련한다.
Joint Learning
Online diffusion model에 대한 훈련 목표:
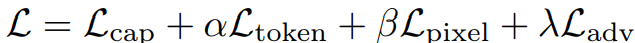
Experiment

확실히 정렬 좋음.
CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
The text-to-image diffusion model (T2I-Model) first generates an image according to the text prompt. Then the image is sent to the Concept Matching module, Attribute Concentration module, and Fidelity Preservation module to compute the loss for fine-tuning
caraj7.github.io



