Abstract
Vision dataset의 이미지를 recaption 하여 공간 중심적 데이터셋인 SPRIGHT 제작
[Github]
[arXiv](2024/04/01 version v1)
The SPRIGHT Dataset
LLaVA-1.5를 활용하여 기존 데이터셋의 600만 개의 이미지에 대해 다음과 같은 prompt로 recaption 하여 SPRIGHT dataset 생성.

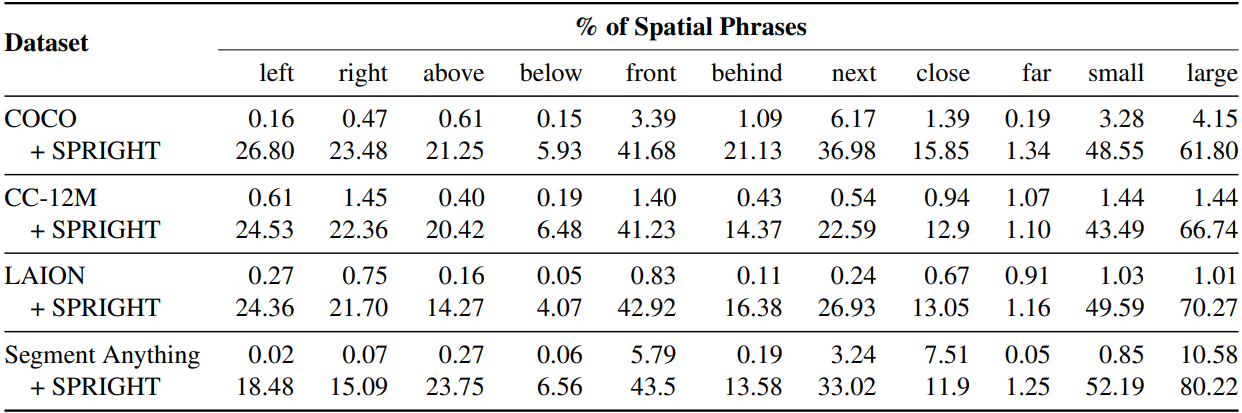
Improving Spatial Consistency
SPRIGHT를 효율적으로 활용할 수 있는 방법 제안.
15000개 미만의 이미지가 포함된 데이터셋에서 1:1 비율로 SPRIGHT와 일반 캡션을 샘플링하여 U-Net과 CLIP text encoder를 fine-tuning.

Efficient Training Methodology
사용된 데이터셋을 개체 수를 기준으로 분할하고 각 분할의 이미지를 사용하여 CLIP text encoder만 fine-tuning.
개체 수가 많은 이미지를 사용했을 때 더 공간 점수가 높았다.
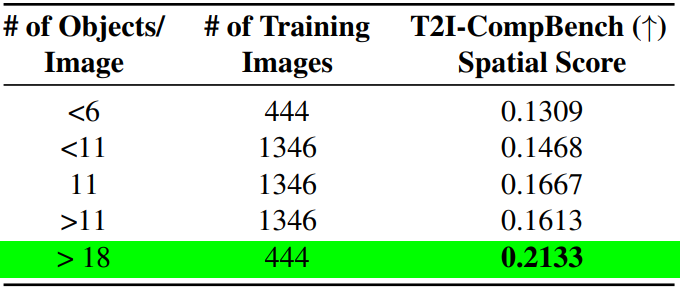

이미지 품질은 떨어지는 느낌. 공식 github에서도 이 설정을 사용하지 않았다.

Ablations
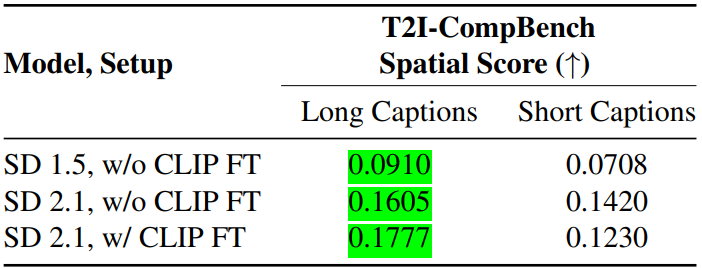
공간 캡션의 비율

공간 캡션의 길이