Abstract
Layout에 맞는 이미지를 생성할 수 있는 Bounded Attention 제안
[arXiv](2024/03/25 version v1)
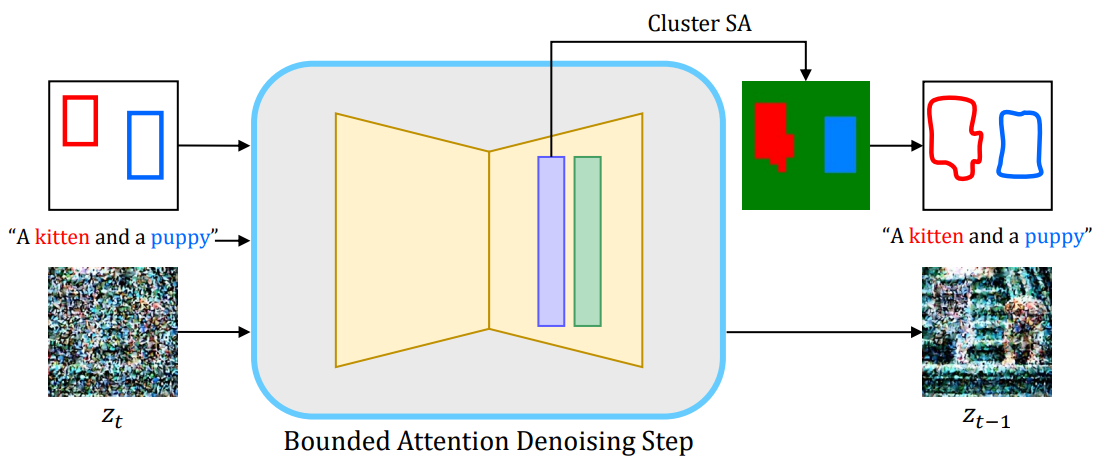
Bounded Attention

Bounded Guidance
0, −∞로 채워진 마스크 M을 사용해 다른 subject의 영역이 mask 된 bounded attention map을 구성할 수 있다.

각 subject에 대해 다음과 같은 손실을 집계한다.
Subject의 bounding box와 관계없는 잠재 픽셀에 할당된 attention score가 높을수록 손실이 크다.

i = subject index,
x = 잠재 픽셀 좌표, query,
c = key (cross attention의 경우 text condition, self attention의 경우 다른 픽셀),
 = attention head와 layer에 걸쳐 집계한 bounded attention map,
b = subject의 bounding box,
C = subject와 관련된 key (subject를 나타내는 token, bbox 내의 픽셀)
집계한 손실을 이용하여 zt를 최적화.

Cross-attention에 적용하면 subject’s semantic의 지역화가 촉진되며, self-attention에까지 적용하면 모호한 subject의 경계에 대한 제어를 추가로 촉진한다.
Guidance는 초기 timestep [T, Tguidance] 동안만 적용.
Bounded Denoising
Coarse masking으로는 고품질 이미지를 생성하지 못한다.
따라서 각 bbox를 self-attention map을 클러스터링하여 얻은 segmentation mask로 대체한다.

Cross-attenion
1. Prompt에 있는 접속사, 위치 관계, 숫자 등이 의도한 layout을 방해할 수 있으므로 POS tagger를 이용해 제외.
2. Subject token은 지정된 영역 내의 픽셀과만 상호작용한다.

Self-attention
1. Guidance와 동일하게 다른 subject의 영역만 제외한다. 배경을 포함해야 자연스러운 이미지를 생성할 수 있다.
2. Cross-attention과 달리 classifier-free guidance의 조건과 무조건 term 모두에 적용해야 아티팩트가 발생하지 않는다.
Segmentation Mask
노이즈에 강한 middle block과 첫 번째 up block의 attention map을 layer, timestep에 걸쳐 집계한다.
Self-attention map을 클러스터링하고 cross-attention map을 통해 subject index를 라벨링한다.
Timestep에 따라 subject의 윤곽이 달라지기 때문에 일정 간격마다 재계산.
Experiments
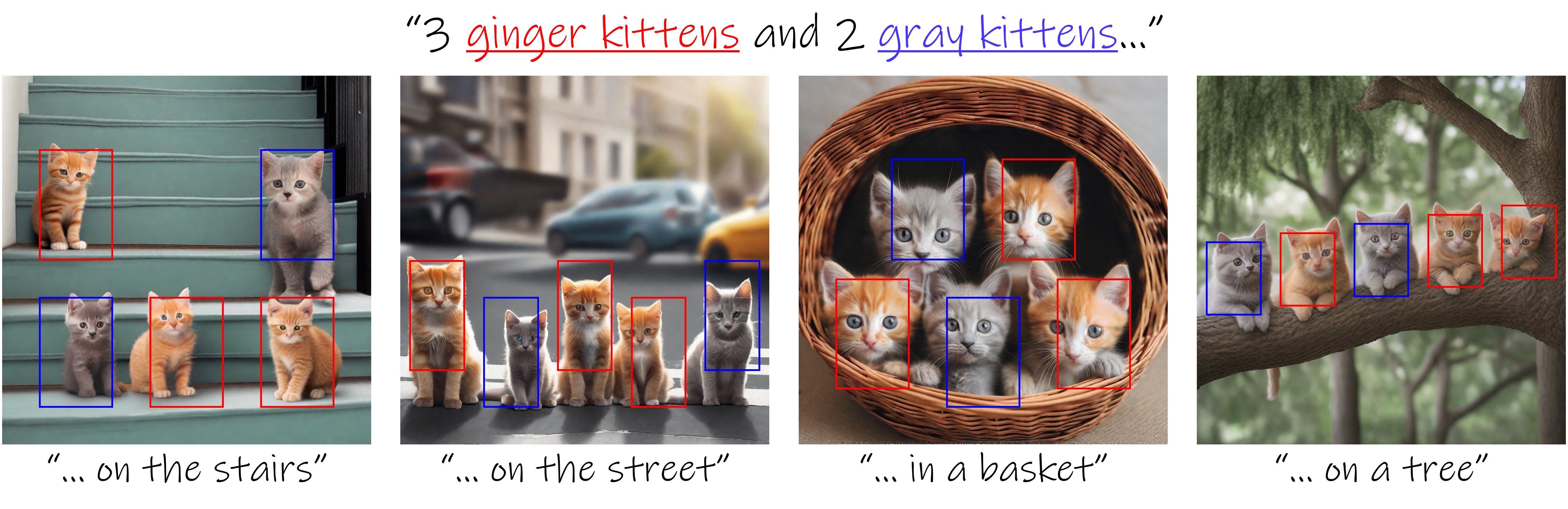
예제

비교




