[Github]
[arXiv](2024/02/27 version v1)
성능이 말도 안 된다;; 그냥 미쳤다 이건;;
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
Abstract
3D model, face landmark 등 강한 조건을 사용하지 않고 원활한 프레임 전환, 일관된 ID가 보장된 비디오 생성
Method
Network Pipelines
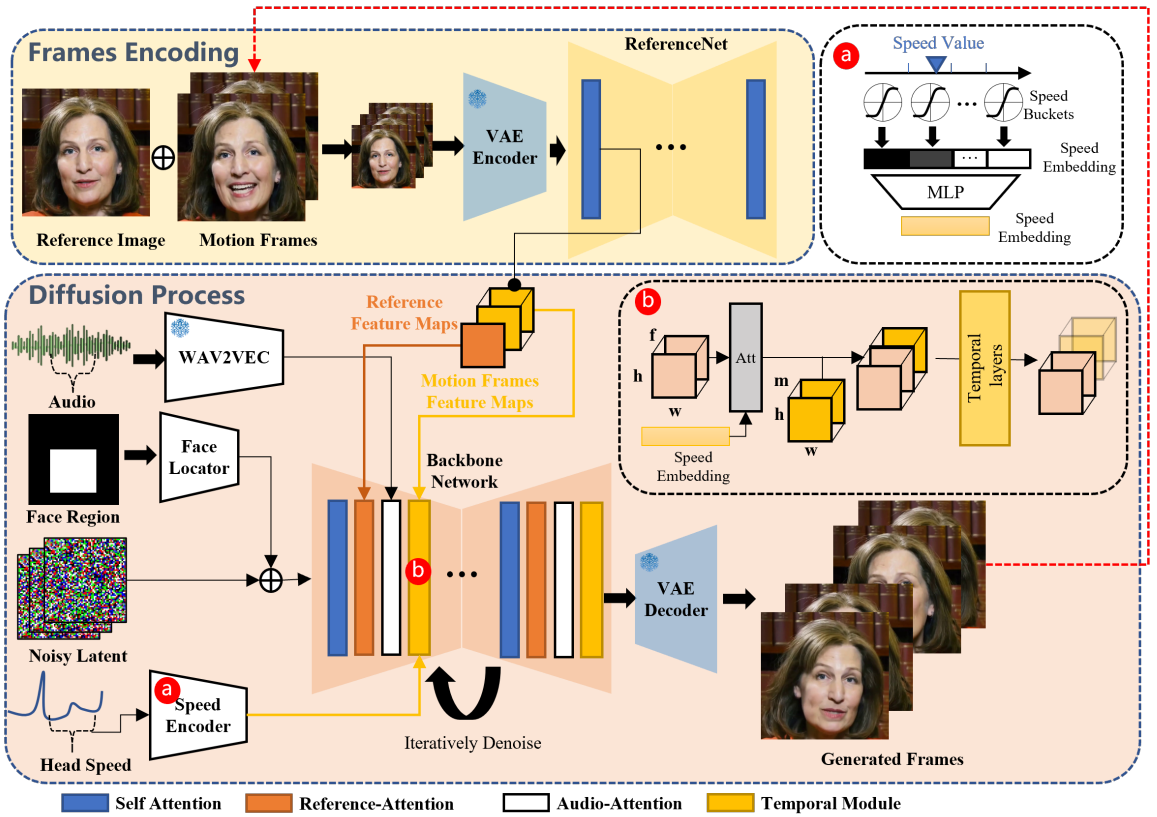
Backbone Network
Stable Diffusion 1.5 기반
Audio Layers
wav2vec 모델을 통해 각 프레임에 대한 음성 표현 추출. 백본에 audio-attention layer 추가.
모션은 숨을 들이쉬고 내쉬는 등 주변 프레임의 영향을 받기 때문에 이들을 연결하여 각 프레임의 음성 feature를 정의한다.
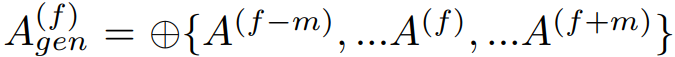
ReferenceNet
ReferenceNet은 백본과 동일한 구조를 가진다. 그렇기 때문에 두 network의 feature map은 유사할 가능성이 높다.
Target의 ID를 reference-attention layer를 통해 백본에 주입한다.
Temporal Modules
AnimateDiff와 유사하게 Temporal-attention layer를 각 해상도에 추가한다.
입력 feature의 차원을 재정렬하여 프레임에 걸쳐 self-attention을 수행.
긴 프레임의 비디오를 생성하기 위해 'motion frame'이라고 불리는 마지막 n개의 프레임을 ReferenceNet에 공급하여 feature map을 추출하고 다음 clip의 temporal module에서 프레임 차원에 추가한다.
T step의 denoising 동안 ReferenceNet은 한 번만 계산되므로 추론 시간이 크게 증가하지 않는다.
Face Locator and Speed Layers
1. 강한 제어는 자유도가 제한되기 때문에 얼굴 영역만 경량 conv layer로 인코딩하여 입력한다.
2. 부드러운 모션을 생성하기 위해 얼굴의 회전 속도를 오디오와 유사하게 임베딩하고 cross-attention으로 주입한다.

얼굴 회전 속도는 정확하게 추정하기 어렵기 때문에 일정 범위의 버킷을 사용하며, 결국 두 요소 모두 약한 제한을 통해 일정한 자유도를 부여한다.
Training Strategies
백본, ReferenceNet의 가중치는 SD로 초기화, temporal layer는 AnimateDiff로 초기화.
백본, ReferenceNet, Face Locator를 이미지에 대해 훈련
→ Temporal, Audio layer를 추가하여 비디오에 대해 훈련
→ Speed layer를 추가하여 Temporal, Speed layer만 훈련
Speed layer와 Audio layer를 동시에 훈련하면 동작에 대한 오디오 구성 능력이 약화되었다고 한다.
Experiments
EMO
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
humanaigc.github.io
'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| Dataset Diffusion: Diffusion-based Synthetic Dataset Generation for Pixel-Level Semantic Segmentation (0) | 2024.03.29 |
|---|---|
| Be Yourself: Bounded Attention for Multi-Subject Text-to-Image Generation (0) | 2024.03.28 |
| ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment (0) | 2024.03.14 |
| Multi-LoRA Composition for Image Generation (3) | 2024.03.08 |
| SDXL-Lightning: Progressive Adversarial Diffusion Distillation (3) | 2024.03.06 |
| Neural Network Diffusion (3) | 2024.03.05 |



