[arXiv](2024/03/02 version v3)

Abstract
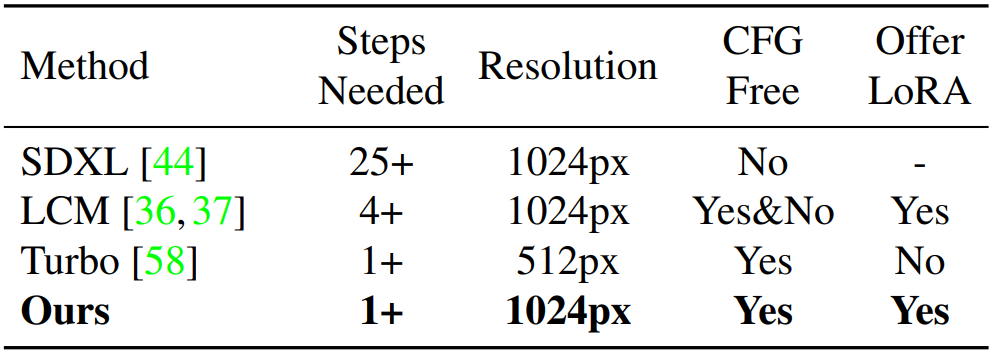
Progressive, adversarial distillation을 결합하여 1-step으로 1024x1024 이미지 생성
Background
LoRA, LCM-LoRA는 LoRA를 통해 증류를 수행할 수 있다는 것을 보여주었다.
Method
- Why Distillation with MSE Fails
- Adversarial Objective
- Discriminator Design
- Relax the Mode Coverage
- Fix the Schedule
- Distillation Procedure
- Stable Training Techniques
Why Distillation with MSE Fails
유한한 훈련 샘플이 데이터 분포를 모호하게 만들며 multi-step을 사용하는 경우 더 많은 비선형성을 갖게 되어 분포가 복잡해진다. 증류된 모델의 부드러운 latent traversal(적은 단계를 사용하므로)로는 이러한 복잡한 분포를 완벽하게 일치시킬 수 없고, 이는 MSE 손실을 통한 직접 증류가 흐릿한 결과를 생성하는 이유이다.
Adversarial Objective
대신 적대적 목표를 사용한다.
학생 예측 x̂t-ns와 교사 예측 xt-ns에 대해 판별자 D는 주어진 조건 (xt, c)에서 교사로부터 생성된 이미지인지 판별한다.

Non-saturated adversarial loss를 활용하여 판별자와 학생 모델을 교대로 훈련한다.
교사 모델의 출력이 xt에 대해 결정적이므로 D에 xt를 제공하는 것은 중요하다.
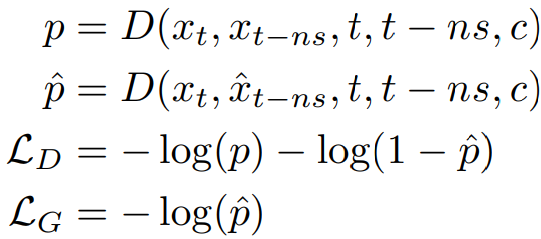
Discriminator Design
GAN이 아닌 mid block까지의 SDXL U-Net encoder를 백본으로 prediction head를 추가하여 판별기로 사용한다.
출력 이미지와 xt를 각각 encoder에 통과시킨 후 연결하고 head와 sigmoid를 통과해 최종 확률을 출력한다.

백본 가중치를 고정하지 않고 전체 판별기를 훈련한다.
Relax the Mode Coverage
적대적 목표가 예리한 flow(분포 변화의 궤적)를 보존하도록 장려하지만 학생 모델이 교사 모델의 분포와 완벽하게 일치할 만큼의 capacity가 부족하다는 것은 변함이 없으며, 적대적 목표가 mode를 무리하게 일치시키려고 하기 때문에 Janus artifact가 나타난다.

의미론적 정확성은 mode coverage보다 중요하다. 때문에 점진적 증류의 모든 단계에서 조건부 목표를 훈련한 다음 무조건 목표의 fine-tuning을 통해 flow 요구 사항을 완화하고 품질을 향상시킨다.

Fix the Schedule
Zero Terminal SNR에 따라 T step은 zero SNR이어야 한다.
샘플링 절차에 대한 최소한의 수정을 위해 T step의 latent를 노이즈로 hard swap 하는 간단한 방법을 채택했다.
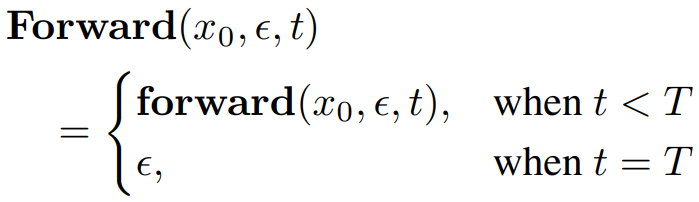
Distillation Procedure
먼저 MSE 손실로 128 → 32 steps 직접 증류를 수행한 뒤, 적대적 손실을 통해 점진적으로 증류한다. (32 → 8 → 4 → 2 → 1)
각 점진적 증류 단계에서는 먼저 조건부와 무조건 목표로 LoRA를 훈련한 다음 무조건 목표만으로 전체 U-Net을 fine-tuning 한다. 판별기는 각 증류 단계에서 다시 초기화된다.
메모리 줄이기: Gradient accumulation, VAE slicing, BF16 mixed precision, flash attention, zero redundancy optimizer
Stable Training Techniques
1-step, 2-step 증류의 경우 안정적인 훈련을 위해 추가 기술을 사용한다.
Train Student Networks at Multiple Timesteps
1000 → 0, 1000 → 500 → 0 만 학습하면 되지만, 안정성을 위해 더 많은 timestep에서 훈련한다.

Train Discriminator at Multiple Timesteps
판별기의 백본인 SDXL U-Net은 낮은 timestep에서는 고주파 세부 사항, 높은 timestep에서는 저주파 구조에만 집중하도록 훈련되었다. 따라서 1-step(1000 → 0) 예측에 대해 제대로 된 평가를 내릴 수 없다.
해결책은 교사와 학생 모델의 출력에 노이즈를 추가하여 중간 timestep을 구성하고 판별기에 입력하는 것이다.


어느 정도 훈련된 후에는 t*의 가중치를 {5:1:1:1}로 변경하여 고주파 세부 사항에 집중하도록 함.
Switch to x0 Prediction
1-step 모델에 ϵ-prediction을 사용하면 noise artifact가 발생하기 때문에 x0-prediction으로 전환.
네트워크를 복사하고 다음 방정식을 통해

ϵ을 x0으로 변환, MSE를 사용하여 복사된 모델을 x0-prediction 모델로 전환한다.
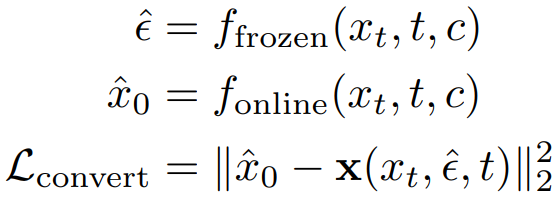
전환 후 적대적 목표로 fine-tuning 하여 품질 향상.
Evaluation