Abstract
요약: Test domain을 알고 있다면 모델을 도메인에 특화하여 retriever가 가져온 문서를 스스로 필터링하도록 훈련할 수 있다.
[Page]
[arXiv](2024/03/15 version v1)
Introduction
LLM을 전문 도메인에 적용할 때 Retrieval Augmented Generation (RAG)와 fine-tuning을 고려할 수 있다.
하지만
- RAG는 고정된 도메인, early access의 이점을 활용하지 못한다.
- Fine-tuning은 문서에 대한 접근 자체가 불가능하다.
LLMs for Open-Book Exam
Closed-Book Exam
Fine-tuning은 외부 문서에 접근하지 못하는 closed-book exam과 같다.
Open Book Exam
RAG는 open-book exam과 같이 외부 문서에 접근할 수 있다.
Domain Specific Open-Book Exam
Domain Specific Open-Book Exam은 기업 문서, 조직의 코드 저장소 등 test domain을 미리 알고 있으며 추론 시에 활용할 수 있는 경우를 말한다.
RAFT
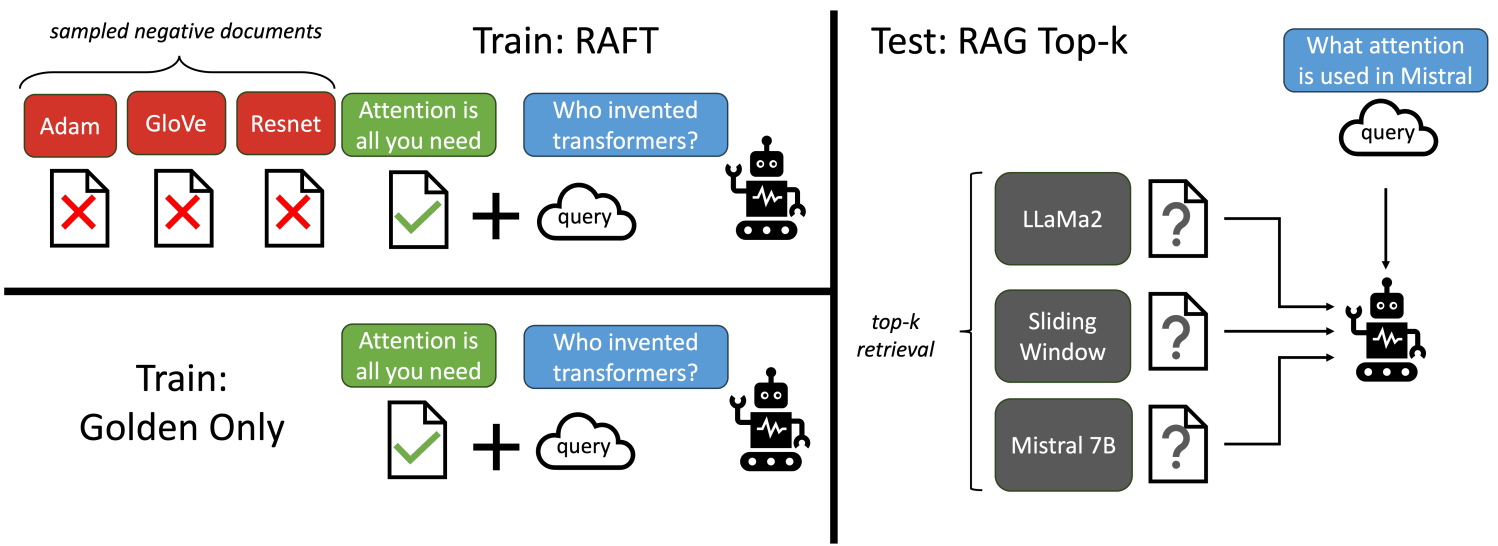
다음과 같은 훈련 데이터를 준비한다.
Q: 질문 (query)
A*: 문서 D*에서 생성된 CoT 스타일의 답변
D: 문서 중 답변과 관련 있는 'oracle' 문서 D*와 관련 없는 'distractor’ 문서 Di를 구분한다.
SFT 시에 q와 함께 D*, Di가 포함된 문서 집합을 모델에 제공하여 더 나은 RAG를 수행하도록 모델을 훈련한다.
또한 (1 - P)의 확률로 D*을 제거하여 검색에 의존하지 않고 답변을 기억하도록 강제한다.
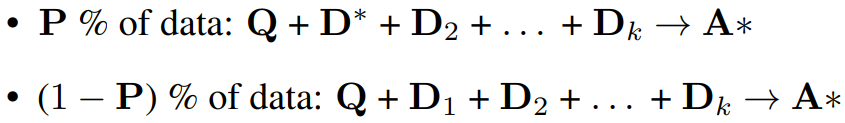
CoT 형식의 답변을 생성하고 참조 문서를 명확하게 인용하도록 하면 품질을 향상시킬 수 있다.

Evaluation
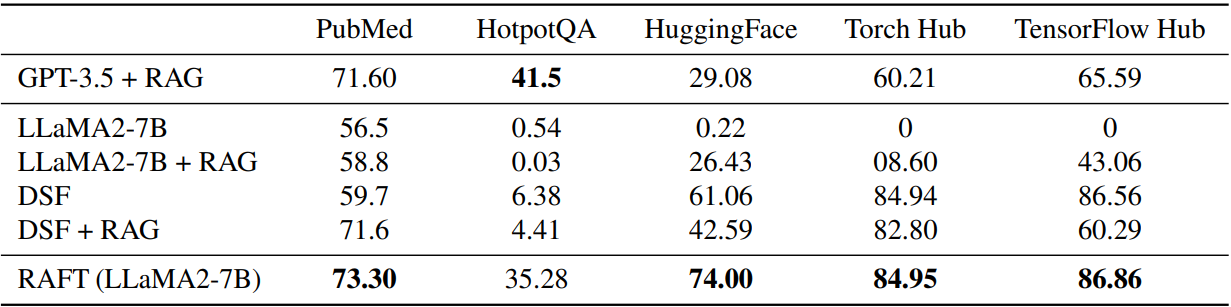
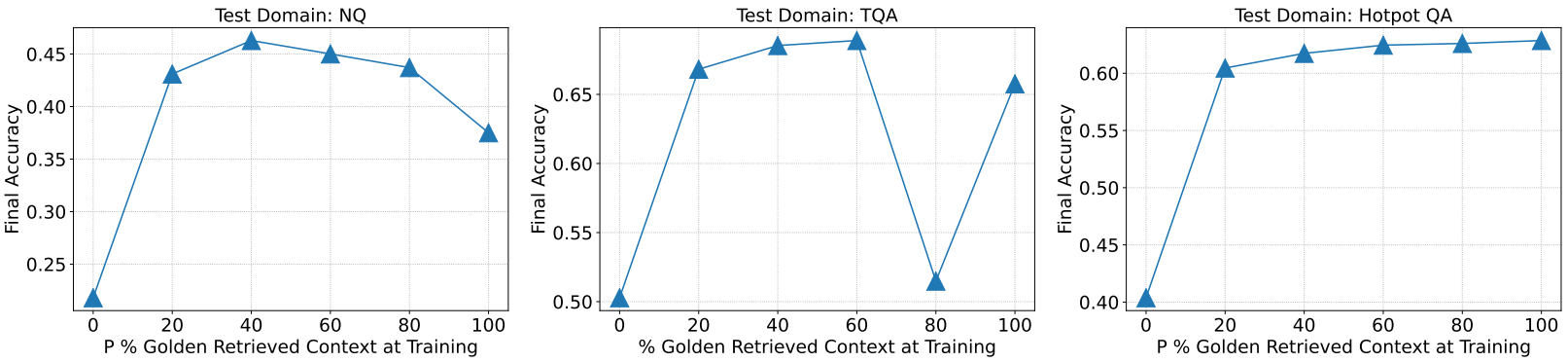
우리의 직관으로는 당연히 검색된 문서 중에 정답이 있어야 할 것 같지만 RAFT에서는 데이터셋에 따라 일부 그렇지 않은 상황이 있을 때 오히려 성능이 좋은 경우도 있었다.
'논문 리뷰 > Language Model' 카테고리의 다른 글
| STaR: Bootstrapping Reasoning With Reasoning (0) | 2024.03.27 |
|---|---|
| DoRA: Weight-Decomposed Low-Rank Adaptation (0) | 2024.03.26 |
| LoRA+: Efficient Low Rank Adaptation of Large Models (0) | 2024.03.22 |
| MoAI: Mixture of All Intelligence for Large Language and Vision Models (0) | 2024.03.19 |
| Chronos: Learning the Language of Time Series (0) | 2024.03.19 |
| Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM (0) | 2024.03.19 |



