[Github]
[arXiv](2024/03/12 version v1)
Abstract
LLM architecture를 이용한 시계열 모델링 프레임워크
Chronos: A Language Modeling Framework for Time Series
본 연구는 아직 실험적인 단계로 아직 많은 보완이 필요하다는 것을 미리 알림.

Time Series Tokenization
시계열 x: C는 과거 context이며 H는 예측 범위.

Scaling
시계열 데이터는 원래의 특성과 패턴을 유지하는 것이 중요하기 때문에 평균을 0으로 정규화하지 않는다.

Quantization
실수 값인 시계열 데이터를 B개의 bin으로 나누어 양자화한다.
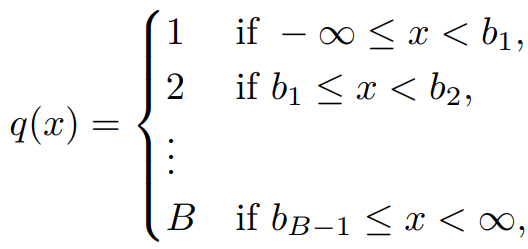
그리고 1 ~ B, PAD, EOS를 time series vocabulary로 사용한다.
이 방법의 단점은 시계열의 범위가 [1, B]로 제한된다는 것이며 이로 인해 추세를 과소평가하는 경향이 있다.
더 나은 방법은 추후에 맡긴다.
Objective Function
LLM에서 일반적으로 사용되는 다음 토큰에 대한 범주형 cross-entropy를 사용한다.
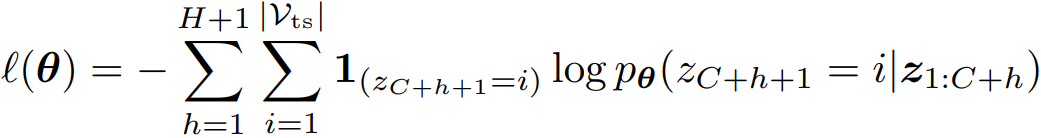
많이 발전된 LLM의 아키텍처나 유틸리티를 사용하기 위해 손실 함수를 그대로 사용하였으며, 범주형 손실은 bin 간의 거리를 명시적으로 인식하지 않기 때문에 시계열 데이터에 적절하지 않을 수 있다.
Data Augmentation
공개된 고품질 시계열 데이터가 부족하기 때문에 실제 데이터를 이용하여 합성 데이터를 생성하는 방법 제안.
TSMix: Time Series Mixup
실제 시계열 데이터를 선형 조합.

KernelSynth: Synthetic Data Generation using Gaussian Processes
다양한 기본 커널이 포함된 kernel bank에서 커널을 샘플링하고 무작위 연산을 통해 조합된다.

Experiments
모델은 T5를 선택했다.
도메인 내, 도메인 외 벤치마크에 대해 평가.

벤치마크 I

벤치마크 II
시계열 쪽은 하나도 모르는데 괜찮은 건가요...?
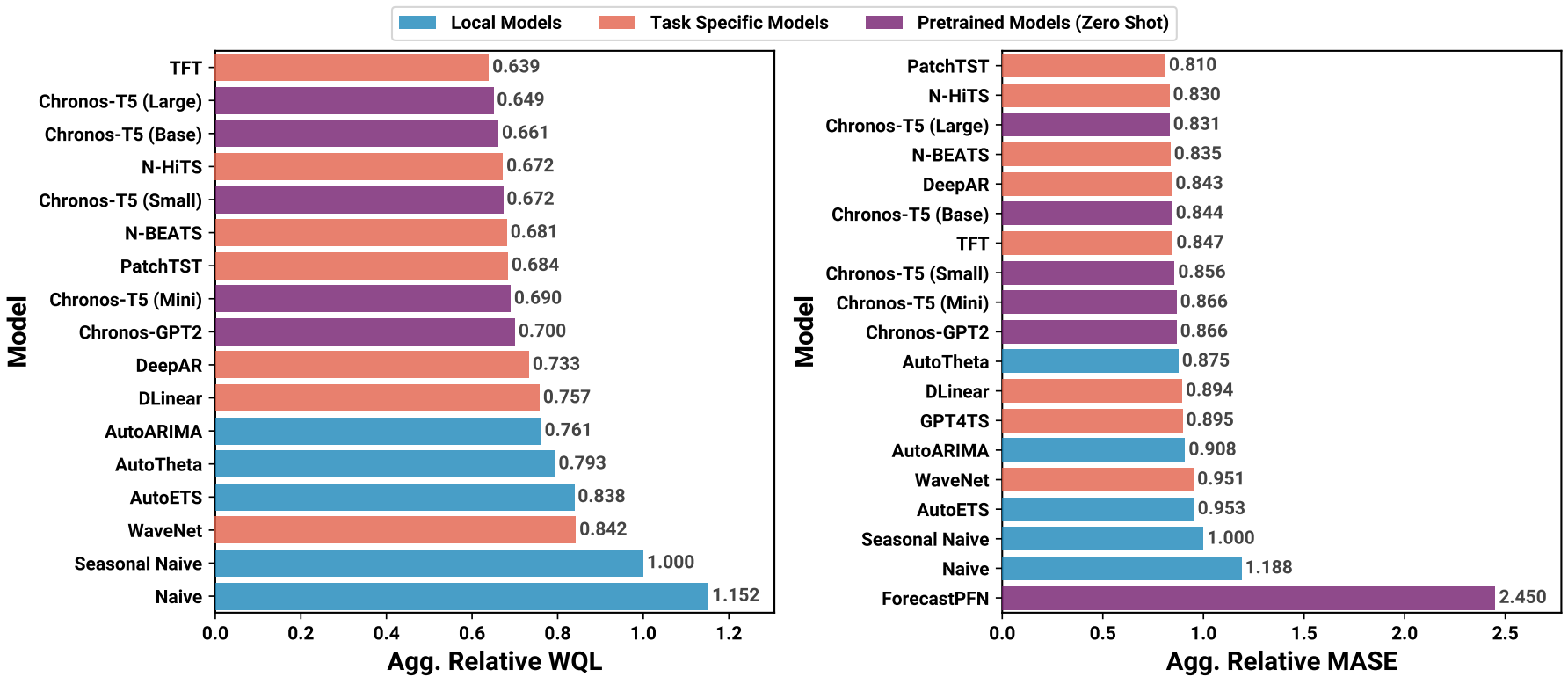
Qualitative Analysis

(b) 지수 추세를 잘 예측하지 못함.
(c, d) 계절 패턴이나 선형 조합으로 이루어진 시계열은 잘 예측함.
Context 길이가 짧은 경우 추세를 과소평가하는 경향.

'논문 리뷰 > Language Model' 카테고리의 다른 글
| LoRA+: Efficient Low Rank Adaptation of Large Models (0) | 2024.03.22 |
|---|---|
| RAFT: Adapting Language Model to Domain Specific RAG (0) | 2024.03.21 |
| MoAI: Mixture of All Intelligence for Large Language and Vision Models (0) | 2024.03.19 |
| Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM (1) | 2024.03.19 |
| GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection (1) | 2024.03.13 |
| The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (0) | 2024.03.11 |



