[Github]
[arXiv](2024/03/12 version v1)

Abstract
Detection, OCR 등의 외부 CV 모델의 출력을 언어화하여 Vision-Language task에 활용하는 MoAI (Mixture of All Intelligence) 제안
MoAI: Mixture of All Intelligence
MoAI는 vision encoder와 MLP, MoAI-Mixer가 장착된 MLM, 외부 CV를 활용하는 MoAI-Compressor로 구성되어 있다.

Vision encoder = CLIP-L/14, MLM = InternLM
Verbalization
Verbalization이라는 과정을 통해 외부 CV model의 출력을 자연어 형식으로 변환.

MoAI-Compressor
Flamingo의 Perceiver Resampler의 구조를 차용했으며 언어화된 CV model의 출력과 학습 가능한 쿼리를 입력으로 받고 쿼리만 MLM에 전달한다.

MoAI-Mixer
MoAI-Mixer는 image & language feature, MoAI-Compressor 출력에 대해 아래 그림과 같이 4개의 cross-attention, 2개의 self-attention을 수행하며 transformer decoder block 이전에 삽입된다.

계산 비용을 줄이기 위해 LoRA를 차용하여 linear projection은 모두 low-rank에서 이루어지고 이 모든 과정은 결국 쿼리에 대한 잔차로 작용하여 입력 토큰을 크게 변경하지 않는다.

First Training Step
Visual instruction tuning dataset으로 MoAI-Compressor, Mixer를 훈련한다.
6개의 각 모듈이 독립적으로 의미 있는 feature를 생성할 수 있도록 하기 위해 시각, 언어 모듈에서 하나씩의 모듈만 선택한다.

Second Training Step
Mixture-of-Experts의 개념을 차용했다.
Compressor, Mixer와 같이 Gating Network를 학습하여 각 모듈에 대한 최적의 가중치 조합을 찾는다.

Top-k를 채택하지 않고 모든 모듈을 사용하는 이유는 단순히 성능이 더 좋았기 때문.

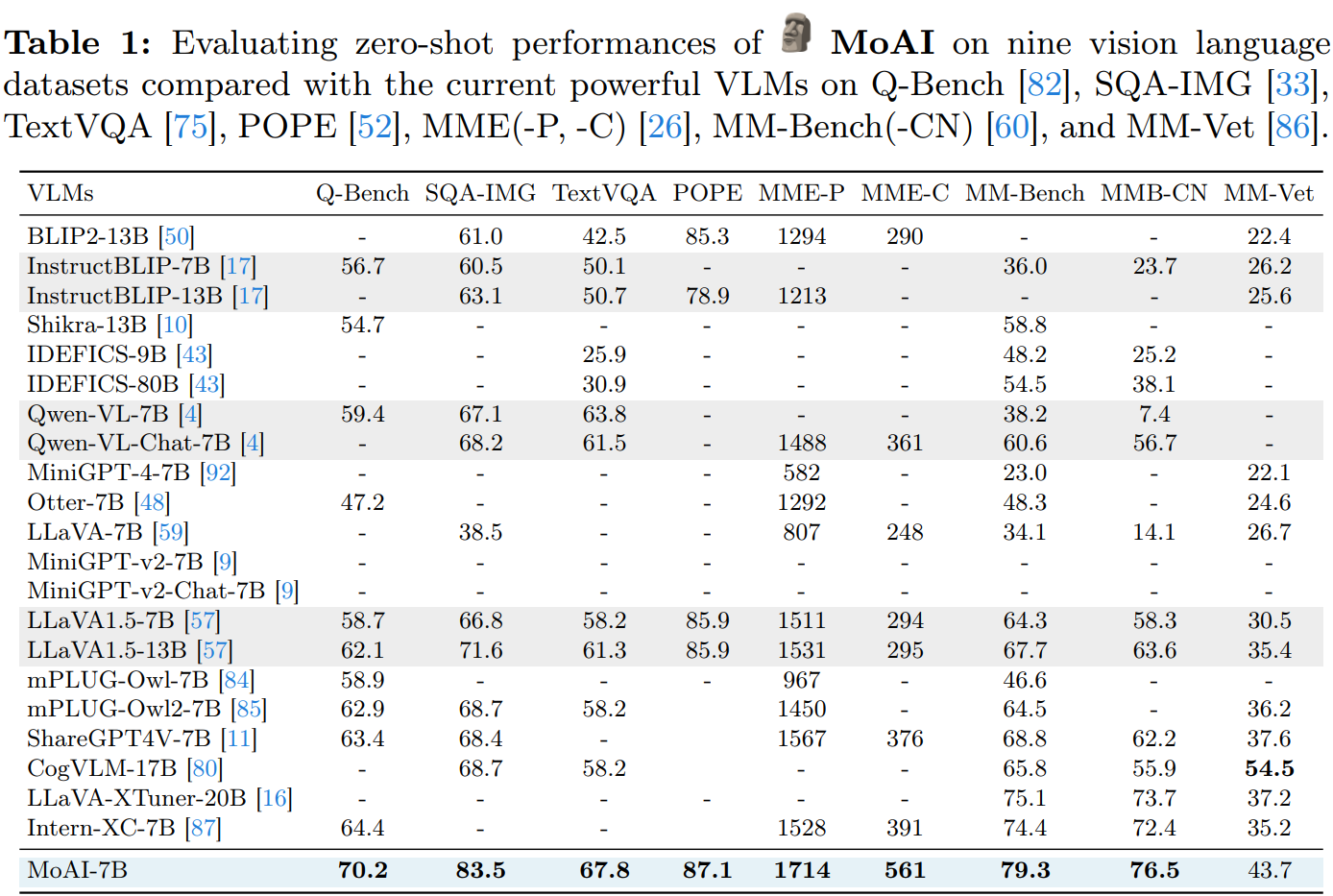
Experiments
MoAI-Compressor: 4계층 transformer 구조이며 학습 가능한 쿼리의 길이는 64.
MoAI-Mixer는 MLM의 몇 개의 레이어에만 삽입된다.
효율적인 추론을 위해 MoAI를 4-bit로 양자화한다.


'논문 리뷰 > Language Model' 카테고리의 다른 글
| DoRA: Weight-Decomposed Low-Rank Adaptation (0) | 2024.03.26 |
|---|---|
| LoRA+: Efficient Low Rank Adaptation of Large Models (0) | 2024.03.22 |
| RAFT: Adapting Language Model to Domain Specific RAG (0) | 2024.03.21 |
| Chronos: Learning the Language of Time Series (0) | 2024.03.19 |
| Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM (1) | 2024.03.19 |
| GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection (1) | 2024.03.13 |



