[Github]
[arXiv](2024/03/06 version v1)

Abstract
Gradient를 low-rank로 투영하여 메모리 집약적인 계산을 수행하는, LoRA 보다 메모리 효율적인 GaLore (Gradient Low-Rank Projection) 제안
GaLore: Gradient Low-Rank Projection
- Background
- Low-Rank Property of Weight Gradient
- Gradient Low-rank Projection (GaLore)
이 챕터 선 한 줄 요약: 훈련이 진행될수록 gradient의 rank가 낮아지며, 이를 이용해 메모리 집약적인 계산을 low-rank에서 수행한다.
Background
Regular full-rank training
Timestep t, optimizer (e.g. Adam) p, 역전파 행렬 G에 대해
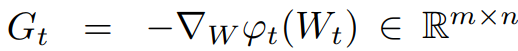
가중치 업데이트는 다음과 같다.

이때 p의 state는 메모리 집약적일 수 있으며 Adam의 경우 G̃는 다음과 같이 계산된다.
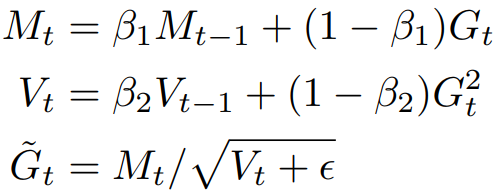

Low-Rank Property of Weight Gradient
Lemma 3.1 훈련이 진행될수록 gradient의 rank가 낮아진다.
Gradient update를 다음과 같은 형태로 가정하면, (B, C는 PSD matrix이다.)
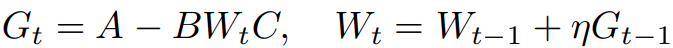
t가 증가함에 따라 G는 rank-1로 수렴한다.
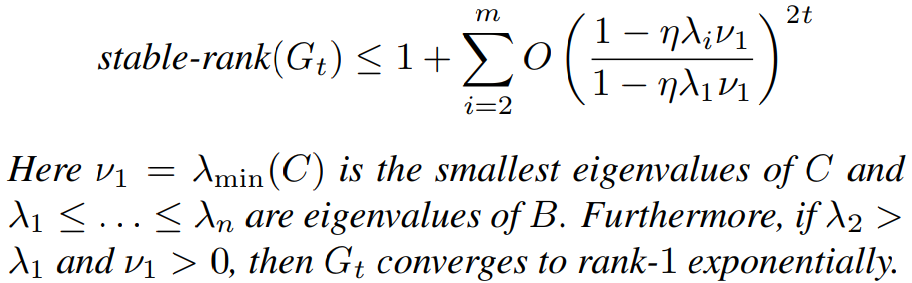
Theorem 3.2 가역 신경망의 gradient form
선형 레이어와 일부 활성화함수는 가역적이다.
다음과 같은 L2 목표를 갖는 가역 신경망 N에 대해

배치 크기 1에서 layer l의 가중치 행렬 W는 다음과 같은 형태의 gradient를 가진다.


Lemma 3.3 Softmax loss를 사용하는 가역 신경망 또한 같은 형태의 gradient form을 갖는다.
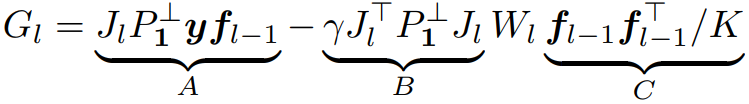
Gradient Low-rank Projection (GaLore)
Definition 3.4 Gradient Low-rank Projection (GaLore)
G를 row-rank로 투영하고 p를 처리한 뒤 원래 차원으로 복구한다.
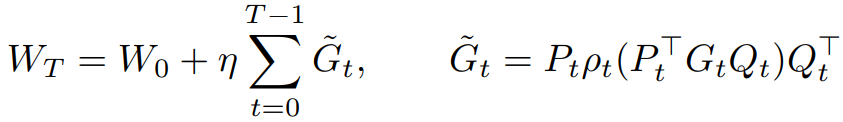
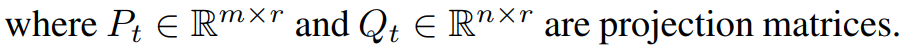
Definition 3.5 L-continuity (Lipschitz continuity)

이를 만족한다는 것은 안정적인 수렴이 보장된다는 것을 의미한다.
Theorem 3.6 Fixed projection을 이용한 GaLore의 수렴
배치 크기가 1보다 클 때의 G:
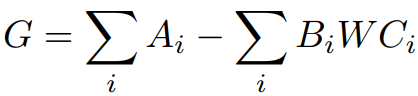
다음과 같은 조건에서 A, B, C에 대한 L-continuity를 만족한다고 한다.
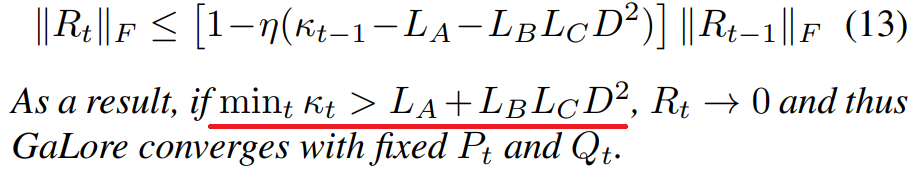
각 변수 정의:


λmin은 해당 행렬이 가진 가장 작은 고윳값을 말한다.
그러므로 조건을 만족하기 위해서는

는 B, C의 가장 큰 몇 개의 고유 부분공간만을 포함하는 것이 좋다.
한 가지 쉬운 방법은 G에 대한 특이값 분해를 사용하는 것이다.

GaLore for Memory-Efficient Training
LLM training과 같은 복잡한 최적화 문제의 경우 단일 subspace로 전체 gradient 궤적을 포착하는 것이 불가능하다.
Composition of Low-Rank Subspaces
훈련 도중 일정 시점에서 현재 G에 대한 특이값 분해를 수행하여 P, Q를 초기화함으로써 다른 subspace로의 전환을 허용한다.


Memory-Efficient Optimization
메모리와 성능 간의 균형을 위해 실제로는 PGQ를 사용하지 않고 PG 또는 GQ로만 투영한다.

Combining with Existing Techniques
추가적으로 QLoRA, Per-layer weight update를 채택.

Experiments
Perplexity


Memory