[Github]
[arXiv](2023/10/17 version v1)
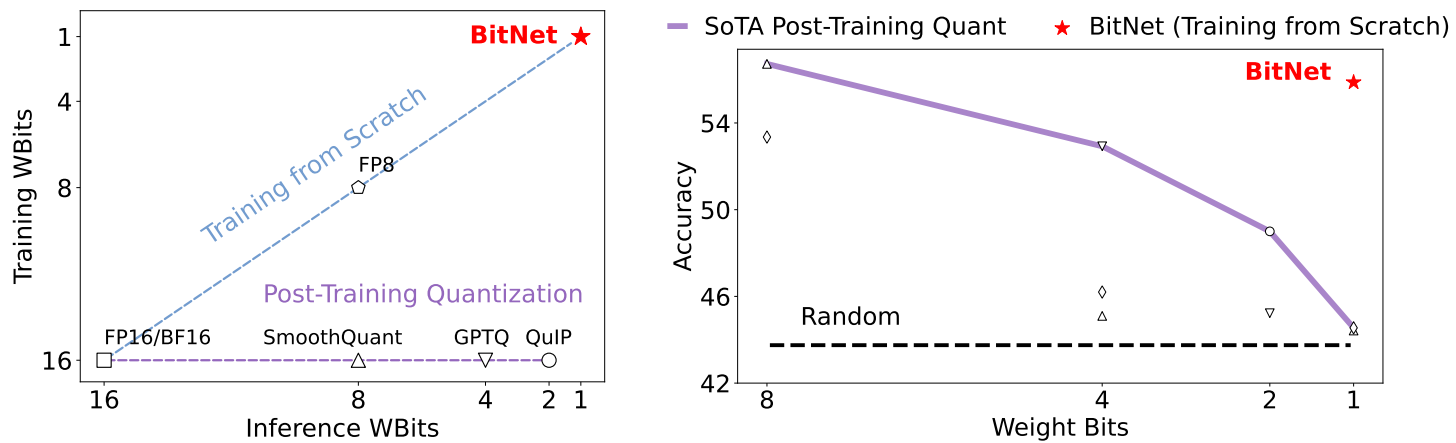
Abstract
가중치를 1-bit로 양자화하는 Transformer architecture
BitNet
아래 그림과 같이 linear 한 연산들을 BitLinear로 교체한다.
대형 모델에서 큰 계산 비용을 차지하지 않는 다른 부분들은 8-bit로 유지하여 입출력의 정밀도를 유지한다.

BitLinear
가중치 W의 평균을 0으로 바꾸고 이진화 후 역 양자화 시 β로 스케일링.
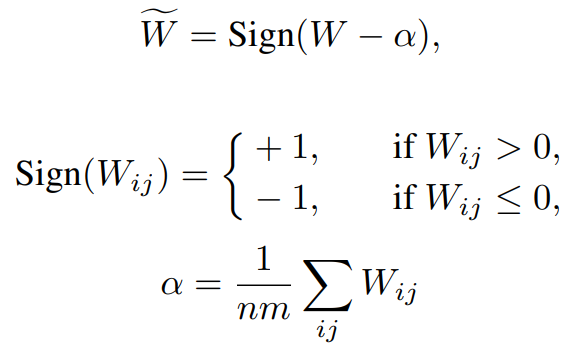
활성화 x는 최대 절댓값을 기준으로 하는 absmax 양자화를 통해 8-bit로 양자화.
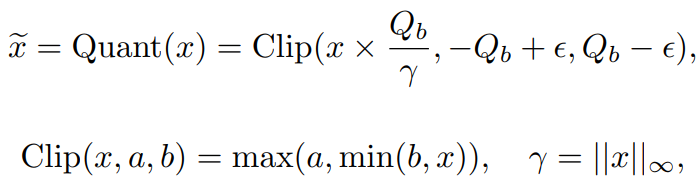
작은 분산은 훈련 안정성에 도움을 주기 때문에 활성화 양자화 전 LayerNorm 적용.
BitLinear 연산 요약:

Model Training
양자화는 미분 불가능하지만 Straight-Through Estimator를 통해 모델을 훈련할 수 있다.
BitNet은 quantization aware training 모델이며, 훈련된 모델을 양자화하는 것은 불가능하다.
이 논문에서와 같이 gradient와 optimizer state는 고정밀도로 유지되고 forward process 시 즉시 이진화된다.
잠재 가중치에 대한 조금의 업데이트는 1-bit로 양자화되는 가중치에서 효과가 없다. 따라서 큰 학습률을 사용한다.



