[arXiv](2024/02/22 version v1)
Abstract
가중치 공유 등 여러 기술들을 활용하여 매우 효율적인 on-device LLM

SwiGLU
Vanilla FFN (FC → ReLU → FC)을 SwiGLU로 변경하면 성능이 향상된다.
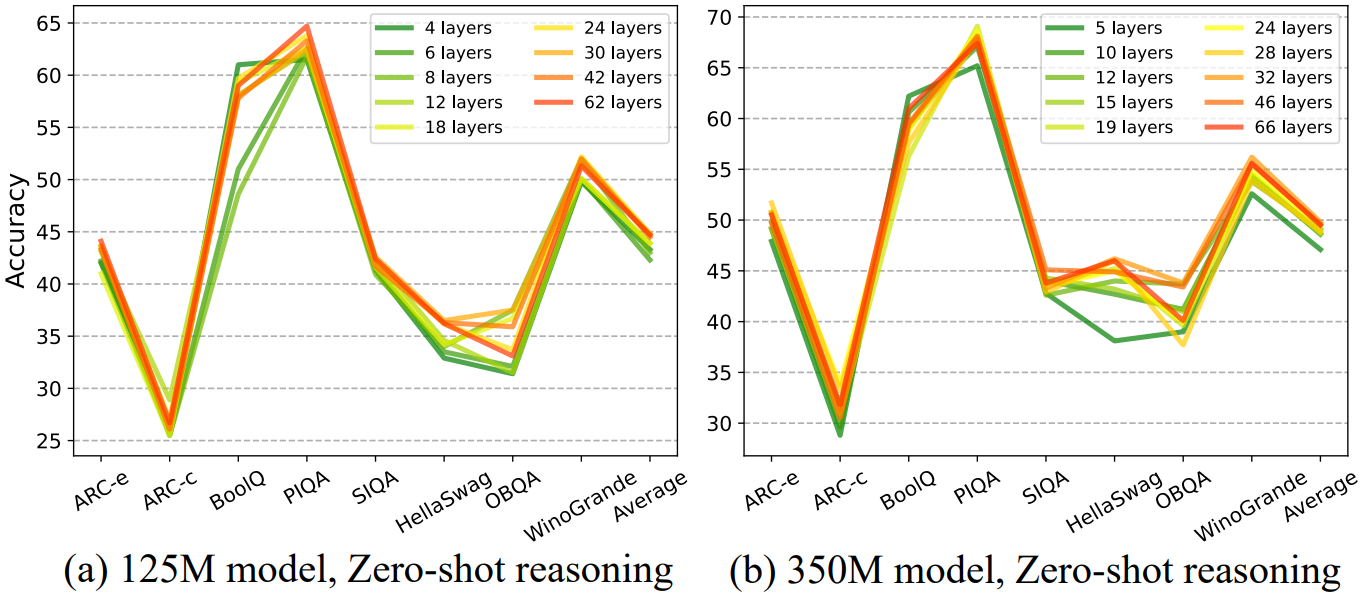
Deep and thin
소형 모델에서는 모델 구조 또한 중요하다. 깊은 모델이 더 성능이 좋았다.
Embedding Share
임베딩 계층의 피라미터는 대형 모델에서는 사소하지만 소형 모델에서는 큰 비중을 차지한다.
입출력 임베딩의 가중치 크기는 (vocab_size, embedding_dim)으로 같기 때문에 공유하여 피라미터를 크게 줄일 수 있다.
떨어진 정확도는 소량의 레이어(=2)를 추가하면 복구할 수 있다.

MQA
(GQA인데 왜 MQA로 표기돼 있음?)
LLaMA 2에서 사용한 Grouped-Query Attention을 채택했다.

16개의 Q-head, 4개의 KV-head를 사용했으며 동시에 임베딩 차원을 늘려 모델 크기를 유지하면 정확도가 상승했다.
Layer Sharing
위에 언급했듯이 소형 모델에서는 깊은 구조가 유리하다. 추가 피라미터 없이 레이어를 늘리기 위해 레이어 공유 사용.
여러 가지 레이어 공유 방법 중 Repeat-all-over share가 가장 성능이 좋았으나

mobile device의 메모리를 감안할 때 즉시 2번 계산하여 SRAM과 DRAM 간에 가중치 전송이 필요 없는 즉각적인 블록 공유 (b)를 채택하였다.

Experiments