[arXiv](2024/02/27 version v1)
Abstract
Ternary quantization {-1,0,1}을 통해 고정밀도 LLM과 같은 성능의 BitNet b1.58 제안

BitNet b1.58
[BitNet] 기반
Quantization Function
먼저 평균 절댓값으로 크기를 조정한 다음 -1, 0, 1 중 가장 가까운 정수로 반올림.
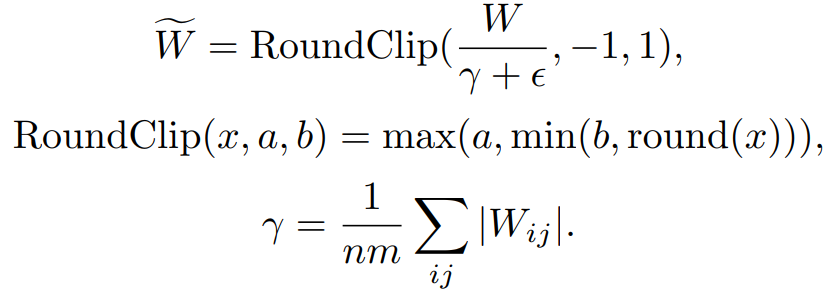
BitNet에서는 ReLU 이전의 활성화는 [0, Q] 범위로 양자화했지만 본문에서는 모든 활성화를 [-Q, Q]로 양자화한다.
구현이나 시스템적으로 깔끔해서 그렇게 했지만, 성능 차이는 거의 없었다고.
LLaMA-alike Components
LLaMA와 같이 RMSNorm, SwiGLU, Rotary embedding, 모든 bias 제거를 채택.
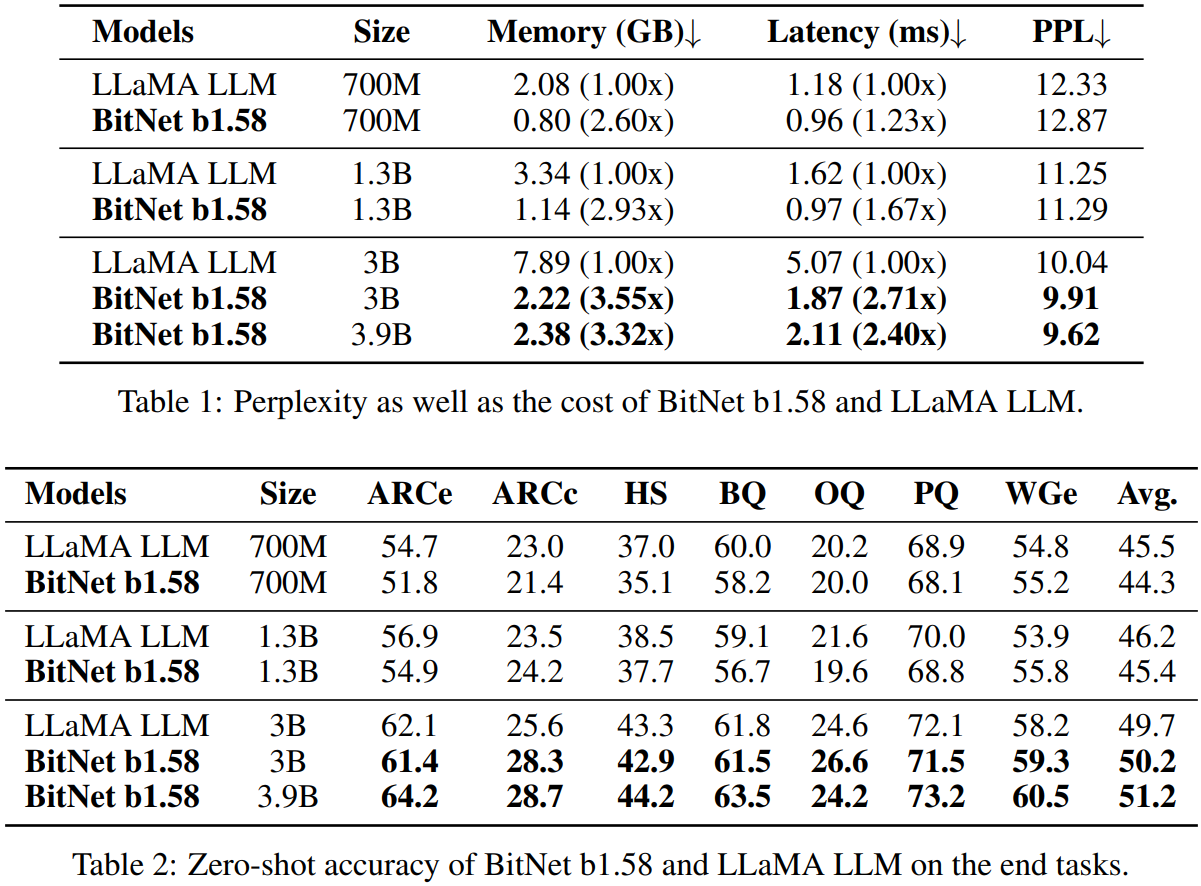
Results