[arXiv](2024/02/16 version v1)
Abstract
Speculation & Verification 통합, Multi-stream attention을 통해 효율적인 speculative decoding.
Introduction
Medusa - 추가 모델이 필요하지 않은 단일 모델 speculative decoding
Speculative Streaming
Streams Design and Initialization
Multi-stream attention을 사용하여 다음 토큰 예측 목표를 n-gram 예측으로 변경. (ProphetNet)

Main stream:

j 번째 speculative stream: Main stream과 이전 speculative stream까지 포함. 이를 MSA layer라고 한다.
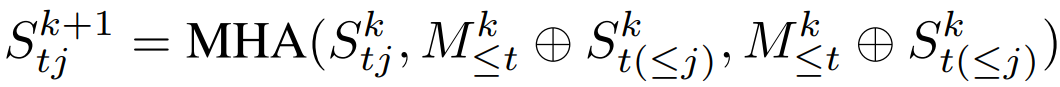
Main stream hidden state의 K/V는 재계산을 피하기 위해 캐시되지만 개별 stream과 관련된 K/V는 저장하지 않도록 하여 메모리 부담을 줄인다.
또한 speculative stream은 전체 N layer 중 마지막 Ns layer만 통과하여 forward pass 계산을 줄인다.
개별 stream의 hidden state는 N - Ns layer에 입력되는 main stream hidden state에 선형 변환을 적용하고 stream identifier embedding을 추가하여 초기화된다.

Parallel Speculation and Verification
Speculative decoding에서 draft model은 target model이 수정본을 발행할 때까지 기다리고, target model 또한 draft model이 초안을 생성할 때까지 기다려야 한다. 본문에서는 이를 효율적으로 병렬화한다.
먼저 한 번의 forward pass로 초안을 생성한다. 트리의 각 단계는 각 speculative stream의 출력 logits에 대한 top-k 샘플링을 통해 구성된다.

이를 펼쳐 모델에 다시 입력한다. 이 tree draft는 다음과 같은 attention mask를 가진다.

입력은 N - Ns 계층을 통과한 후 별도의 early exit head를 통해 토큰 간의 전이 확률을 계산하여 가지치기를 수행한다.
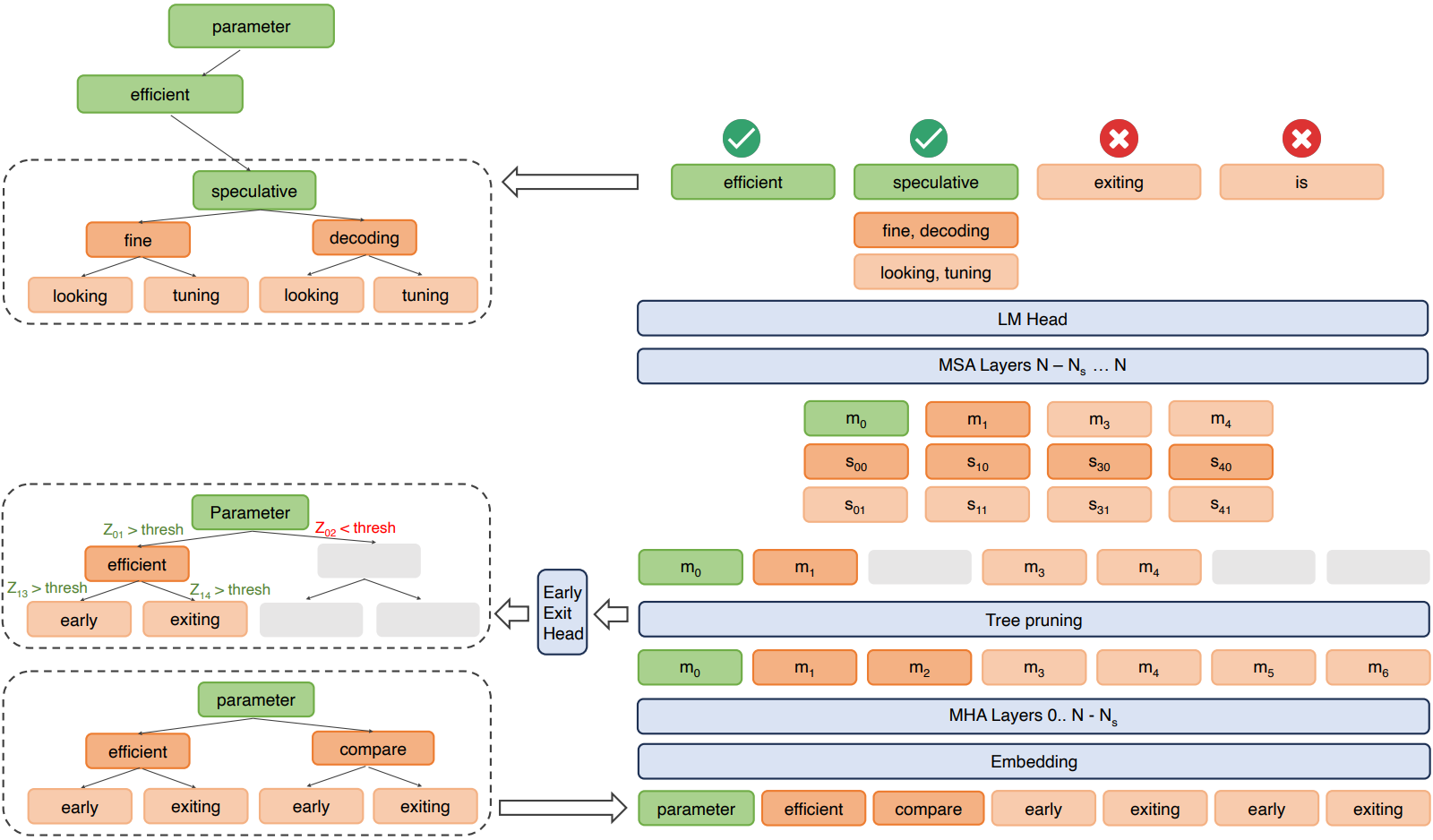
가지치기 후 남은 각 노드에 speculative streams을 삽입하고 나머지 MSA layer를 통과한다.
Verification: 가지치기된 트리에서 main stream이 수용할 수 있는 가장 긴 경로를 찾는다.
마지막으로 허용된 토큰이 새로운 tree root가 되고 해당 토큰의 speculative streams에서 샘플링된 top-k 토큰이 하위 트리를 형성한다.
그림이 잘 이해가 안 될 수도 있는데, 이 LLM은 일단 '다음 토큰을 예측하는 모델'이며, 'parameter'에 대한 main stream의 출력이 'efficient', 'efficient'에 대한 main stream의 출력이 'speculative' 이런 식으로 되는 것이다.
허용 기준에 대한 것은 언급되어 있지 않지만 어쨌든 확률이 낮거나 하는 등의 모종의 이유로 'early'에 대한 출력인 'exiting'과 'exiting'에 대한 출력인 'is'가 거부되었고 (둘 다 같은 계층의 노드이므로 둘 중 하나만 허용되더라도 계속 진행됨.), 마지막으로 허용된 'speculative'가 root로, 해당 토큰의 speculative streams이 하위 노드로 채택된 것이다.
Training Objective
다음의 목표를 통해 base model에 대한 LoRA와 speculative stream과 관련된 피라미터를 공동으로 훈련한다.
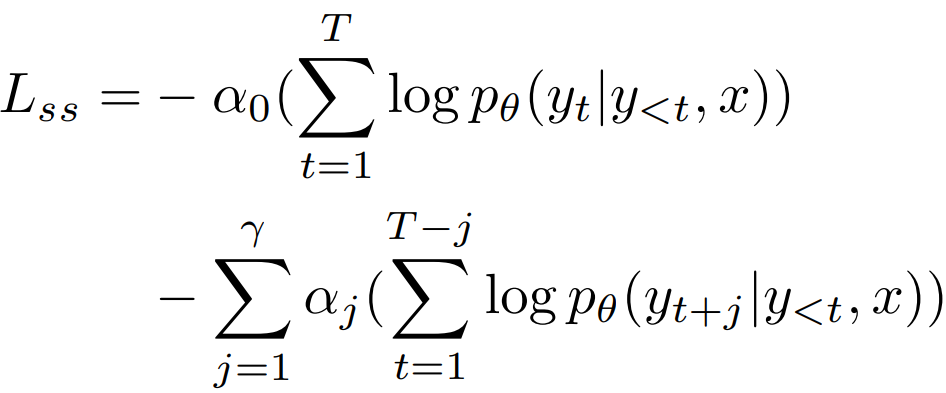
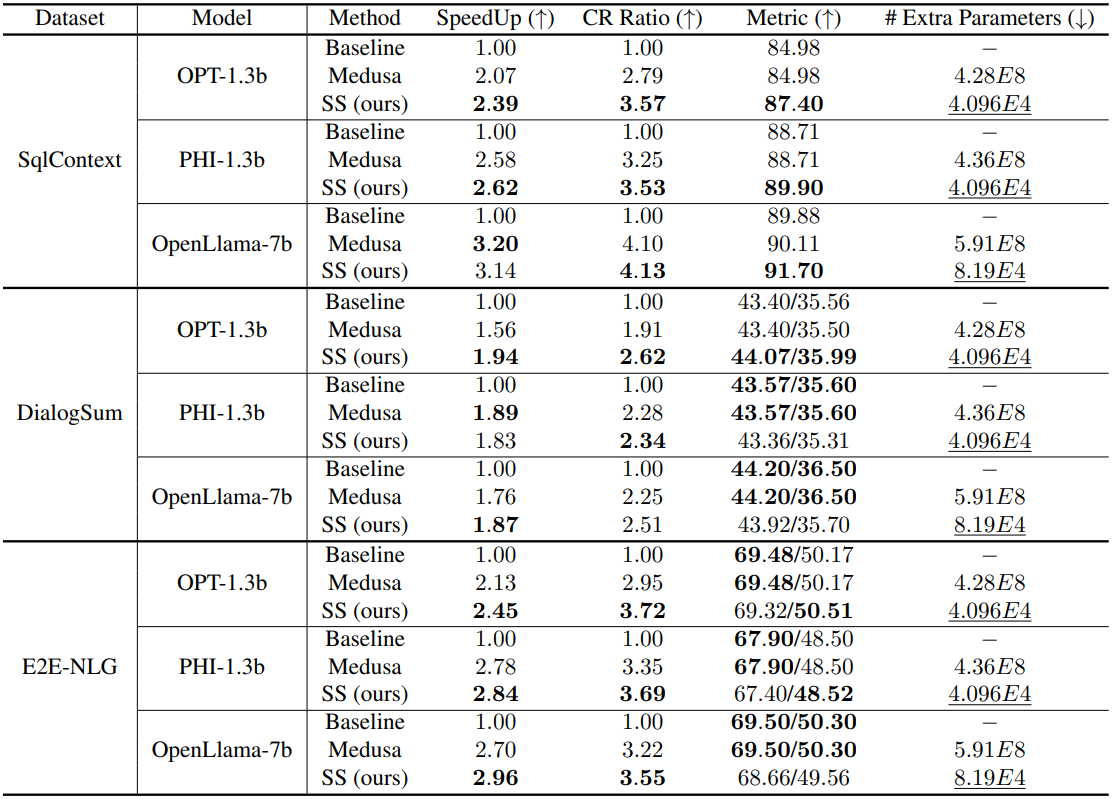
Experiments
Medusa보다 훨씬 적은 추가 피라미터를 가지면서도 대등한 성능을 보여준다.