[Github]
[arXiv](2024/02/12 version v2)
Abstract
SFT data를 활용한 self-play mechanism을 통해 성능을 점진적으로 향상시키는 SPIN (Self-Play fIne-tuNing) 제안
Problem Setting and Preliminaries
LLM의 다음 토큰 예측:

Supervised Fine-Tuning (SFT):
모델의 예측 분포 pθ(y∣x)가 고품질 QA 데이터셋의 분포 pdata(y∣x)와 일치할 때 최소가 된다.

RL Fine-Tuning:
보상 모델 r을 기준으로 보상을 최대화, 안정적인 훈련을 위해 KL regularization 추가.

Self-Play Fine-Tuning (SPIN)
인간과 LLM의 출력을 구분하는 main player와 그를 속이려고 하는 opponent player로 나뉜다.
약간 GAN 느낌. 하지만 실제로 다른 훈련 목표를 가지는 2개의 모델이 있는 건 아님.
Training the Main Player
Main player는 목표 데이터 분포의 응답 y, opponent player의 응답 y' 간의 차이의 기댓값을 최대화하도록 훈련된다.

손실 함수 l을 통해 위 수식 대신, 보다 일반화된 최적화 문제를 풀 수도 있다.

본 연구에서는 logistic loss function을 채택했다.

Updating the Opponent Player
Opponent player는 다음과 같은 기댓값을 최대화해야 한다.
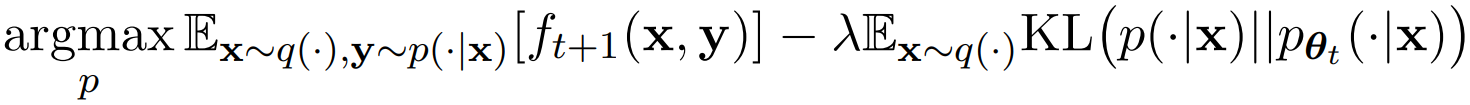
이에 대한 closed-form solution은 다음과 같다.
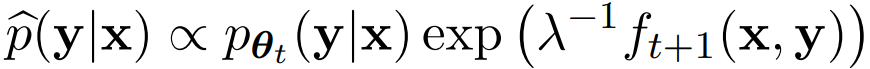
하지만 이상적인 해결책이 LLM의 피라미터 공간 내에 속한다고 보장할 수 없다.
우리는 업데이트가 LLM의 피라미터 공간 내에서 진행되기를 희망하므로 함수 F를 다음과 같이 파리미터화 한다.


End-to-end Training Objective
이전의 두 단계를 단일 end-to-end training objective로 통합한다.


SPIN은 DPO와 비슷하지만 positive-negative pair가 필요한 DPO와 다르게 SFT dataset에만 의존한다.
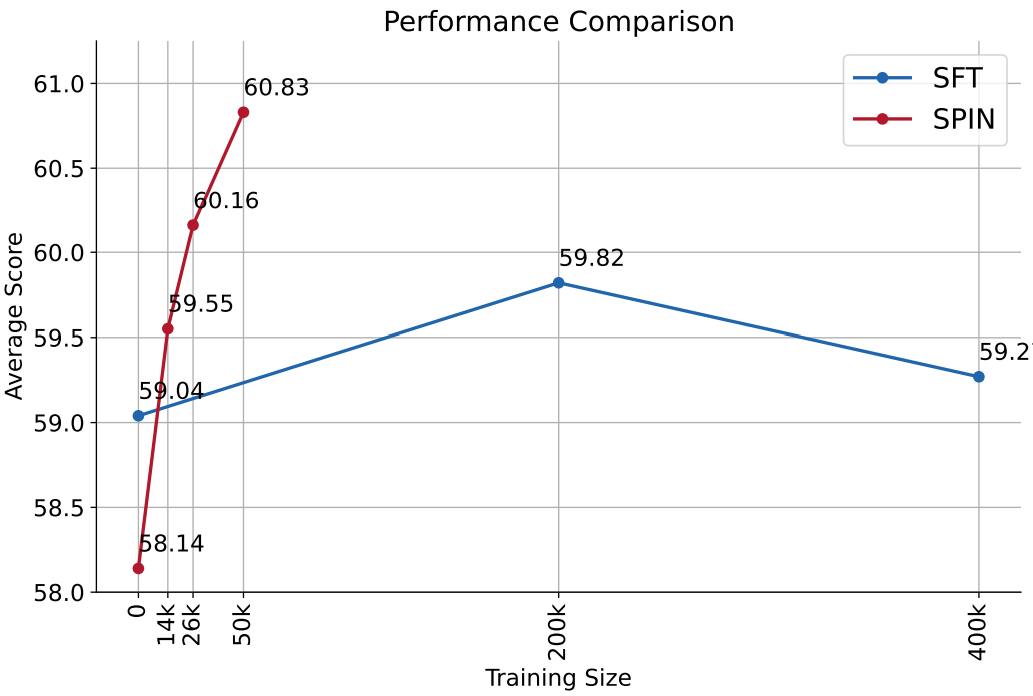
Experiments
적은 데이터로도 SFT보다 좋은 성능