[Github]
[arXiv](2024/02/13 version v1)

Abstract
Ring attention을 활용하여 1M 길이의 context에 대한 multi-modal modeling이 가능한 LargeWorldModel(LWM) 제안
Introduction
- Ring Attention을 통해 context 크기를 1M까지 점진적으로 늘림
- Video, image, text 혼합에 대한 훈련
- 책에서 QA dataset을 생성
Overview
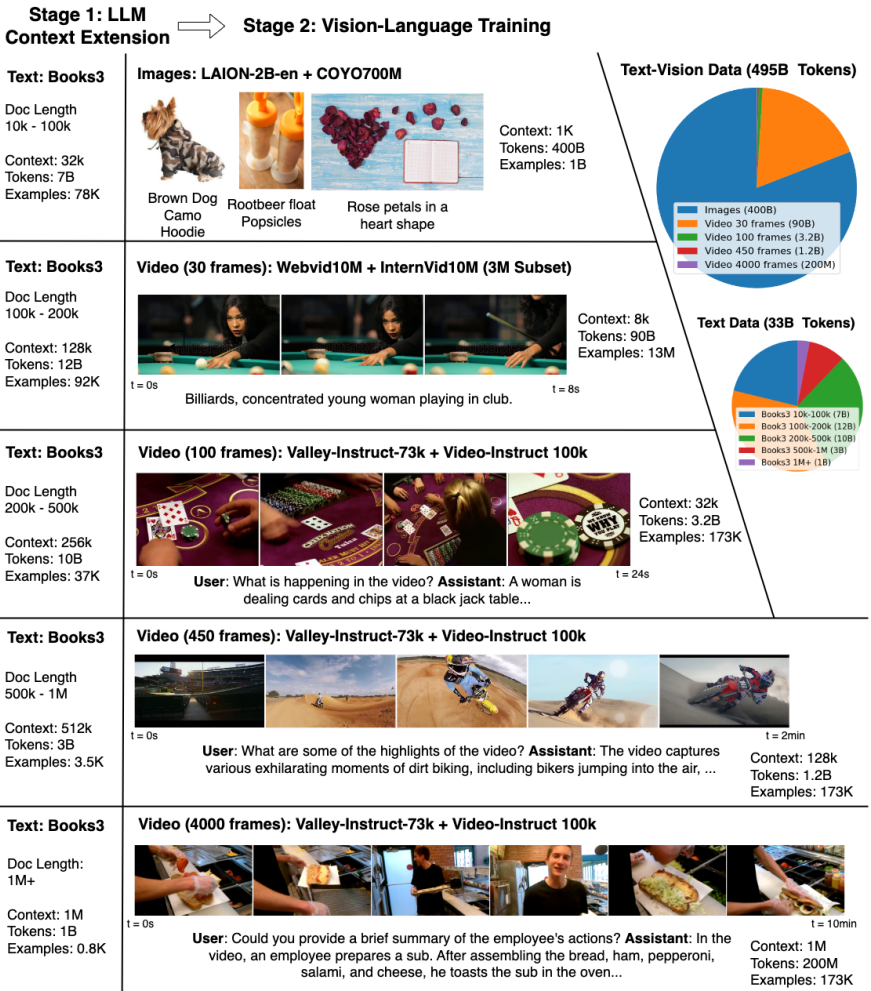
Stage I: Learning Long-Context Language Models
Long-context LM인 LWM-Text, LWM-Text-Chat 개발
Extending Context
Ring attention + Flash attention
Progressive Training on Increasing Context Length
1M 길이의 시퀀스에 대한 훈련은 엄청나게 오래 걸리며 많은 iteration을 훈련하지 못한다.
대안으로 시퀀스 길이를 점진적으로 늘리며 훈련하면 짧은 길이 시퀀스에 대한 종속성을 학습하여 최대 길이 시퀀스에서 많은 iteration을 수행하지 않아도 된다.
Positional Extrapolation for Long Contexts
간단히 θ 값만 조정하여 다양한 context에 적용할 수 있는 RoPE 채택.
Chat Fine-tuning for Long-Context Learning
Books3 dataset에서 청크 당 1000개의 토큰으로 분리하고 LLM을 통해 해당 청크에 대한 QA를 생성.
Context 길이가 32K로 지정되면 32개의 청크를 합치고 QA를 추가하여 데이터를 제작.
Stage II: Learning Long-Context Vision-Language Models
긴 비디오와 언어에 대한 공동 훈련을 통해 LWM, LWM-Chat 학습.
Architectural Modifications For Vision

aMUSEd의 사전 훈련된 VQGAN을 각 프레임에 적용.
입력을 정의하기 위한 토큰 도입. (<eof>, <eov>, <vision(text)>, </vision(text)>)
모델은 비전과 텍스트의 인터리브된 연결로 학습되고 자기회귀 방식으로 예측함.
Training Steps
LWM-Text에서 시작하기 때문에 이미 1M 시퀀스를 지원한다.
각 단계마다 설명된 데이터를 학습한다.
언어 능력을 보존하는 것이 유익하기 때문에 ~8K까지는 배치의 16%를 순수 텍스트 데이터로 교체한다.
- LWM-1K: 1K 길이의 text-image pair
- LWM-8K: 8K 길이의 text-image, text-video pair의 혼합
- LWM-Chat-32K/128K/1M: 여러 downstream task에 대해 채팅 형식으로 증강된 text-image, text-video instruction data. 각 text-vision pair가 서로에게만 attention을 수행하도록 mask로 가리는 것이 유의미했다.
Experiments
Large World Models
Current language models fall short in understanding aspects of the world not easily described in words, and struggle with complex, long-form tasks. Video sequences offer valuable temporal information absent in language and static images, making them attrac
largeworldmodel.github.io
'논문 리뷰 > Language Model' 카테고리의 다른 글
| Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models (SPIN) (0) | 2024.02.26 |
|---|---|
| Generative Representational Instruction Tuning (GRIT) (0) | 2024.02.26 |
| Chain-of-Thought Reasoning Without Prompting (CoT-decoding) (1) | 2024.02.26 |
| More Agents Is All You Need (1) | 2024.02.21 |
| BiLLM: Pushing the Limit of Post-Training Quantization for LLMs (0) | 2024.02.21 |
| Self-Discover: Large Language Models Self-Compose Reasoning Structures (0) | 2024.02.20 |



