Block-wise attention의 병렬화 방식을 개선하여 무한에 가까운 context로 확장
[Github]
[arXiv](Current version v3)
Abstract
이전의 메모리 효율적인 transformers 보다 훨씬 긴 시퀀스를 훈련하고 추론할 수 있는 Ring Attention 제안
기존 최첨단 기술보다 500배 이상 긴 시퀀스를 훈련할 수 있다고 한다. ㄷㄷ
Introduction
Block-wise 방식으로 self-attention과 FFN을 수행함으로써 시퀀스 차원을 여러 장치(device)에 분산하여 계산할 수 있다.
Ring Attention에서, 각 장치는 지정된 시퀀스 블록에 대한 attention, FFN을 계산한다. 각 장치는 ring을 형성하여 KV 블록을 공유한다.

이렇게 하면 각 장치에는 입력 시퀀스 길이와 무관한 블록 크기의 메모리만이 필요하고, 메모리 제약을 효과적으로 줄일 수 있다.
Ring Attention

먼저 입력 시퀀스를 장치 수만큼의 블록으로 나누고, 각 장치에서 QKV를 계산한다.

K, V를 순환시키면서 각각 계산함.

Ring attention을 가능하게 하는 2가지 특징:
1. Attention의 순서 불변
중간 통계값의 online 재조정을 통해 순서에 상관없이 계산될 수 있다.
2. 장치 간의 통신에 추가 통신 시간이 발생하지 않음
Flash attention 논문에 따르면 GPU는 병렬 연산 시 데이터를 HBM에서 가져온 후 SRAM에 올려놓고 연산을 하는데, 장치 간에 KV 블록을 주고받는 시간이 계산 시간보다 적으면 통신에 의한 추가적인 시간 지연이 발생하지 않는다.
Arithmetic Intensity Between Hosts
(Hidden size d, block size c)
Attention 계산에는 4dc2 FLOPs가 필요하고, 장치 간 통신에는 4cd Bytes가 필요하다. 따라서 블록 크기 c가 F/B 이상이어야 시간 지연이 발생하지 않는다.
Memory Requirement
각 장치는 QKV 블록을 저장하기 위한 3개의 블록 크기, KV를 수신하기 위한 2개의 블록 크기, 출력을 저장하기 위한 1개의 블록 크기가 필요하다. 따라서 장치에는 총 입력 시퀀스 길이 s와 무관하게 6개 블록 크기만큼의 메모리가 필요하다.
따라서 s가 6c보다 작으면 ring attention을 쓰지 않을 때보다 더 많은 메모리가 활성화되므로 비효율적이다.
널리 사용되는 컴퓨팅 서버에 대한 c, s의 최소 조건:

논문 부록에 코드 구현 이씀.
Results
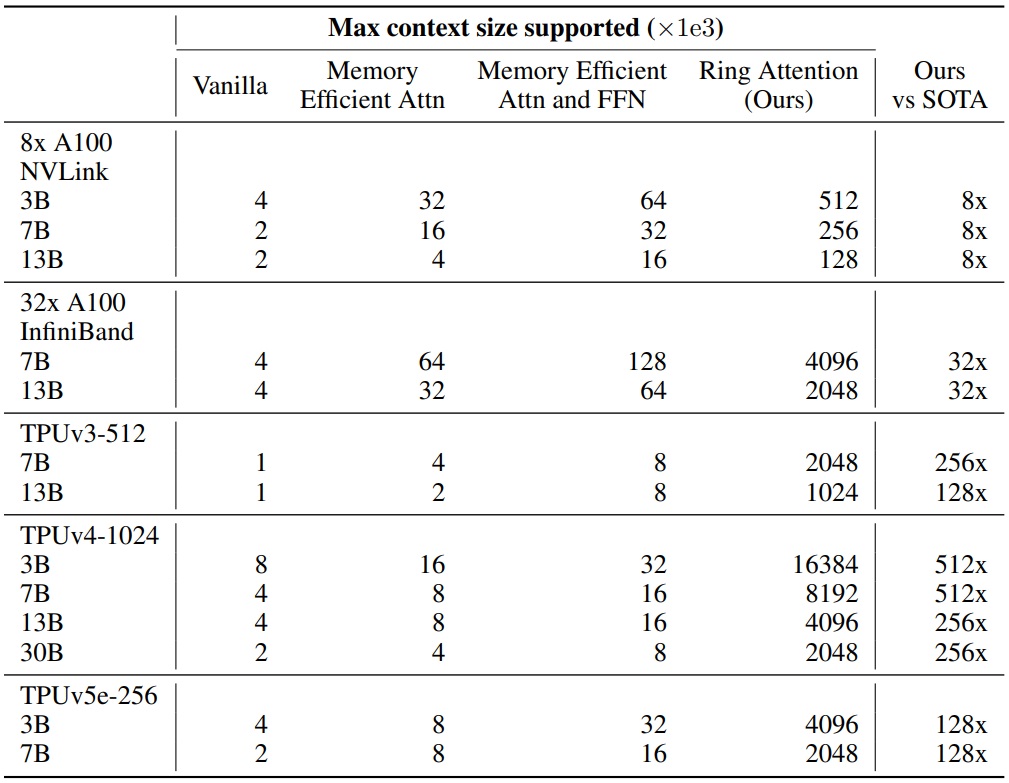

'논문 리뷰 > Language Model' 카테고리의 다른 글
| Unsupervised Dense Information Retrieval with Contrastive Learning (Contriever) (1) | 2023.11.14 |
|---|---|
| GLM-130B: An Open Bilingual Pre-trained Model (0) | 2023.11.13 |
| Sparse Fine-tuning for Inference Acceleration of Large Language Models (0) | 2023.11.03 |
| Self-attention Does Not Need O(n^2) Memory (5) | 2023.10.24 |
| Blockwise Parallel Transformer for Large Context Models (BPT) (1) | 2023.10.24 |
| Blockwise Self-Attention for Long Document Understanding (BlockBERT) (1) | 2023.10.23 |



