희소 모델을 증류 방식을 통해 더 높은 sparse level로 fine-tuning
[Github]
[arXiv](Current version v2)

Abstract
LLM의 sparse fine-tuning에서 더 높은 희소성에서도 정확한 복구를 가능하게 하는 증류 손실의 변형인 SquareHead 소개
Introduction
순진한 sparse fine-tuning은 LLM에 적용하기 어렵다.
- 높은 희소성에서 발산 발생
- Downstream 작업을 위한 적은 양의 fine-tuning data
이를 해결하기 위해 SquareHead 손실을 사용하여 SparseGPT를 통해 얻은 희소 모델을 fine-tuning 한다.
Methodology
Sparse Fine-tuning
Sparsification
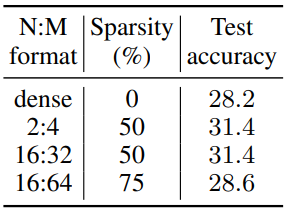
목표 압축 요구 사항을 만족하는 희소 모델 세트를 얻기 위해 모델을 fine-tuning 하면서 희소 수준을 점진적으로 높인다.
Distillation strategies
어려운 LLM의 fine-tuning을 위해 knowledge distillation(KD) 방식을 선택했다.
일반적인 KD의 손실은 학생 모델 Ps와 교사 모델 Pt의 출력에 KL divergence를 구하는 것이다.
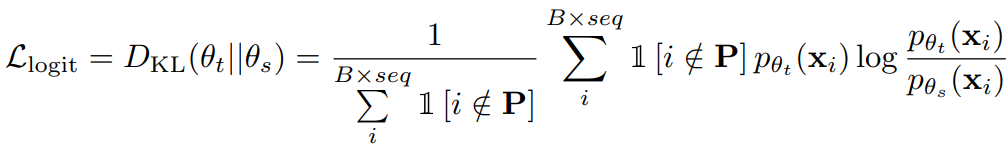
중간 feature에 대한 MSE 손실을 추가하고 이를 Square Head라고 부른다.
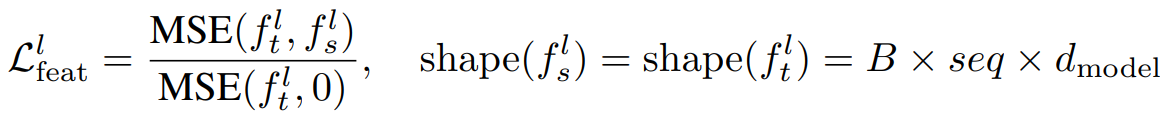
(fl은 l 레이어의 feature map, 분모는 훈련을 안정화하기 위한 정규화 term)
Runtime Acceleration from Sparsity
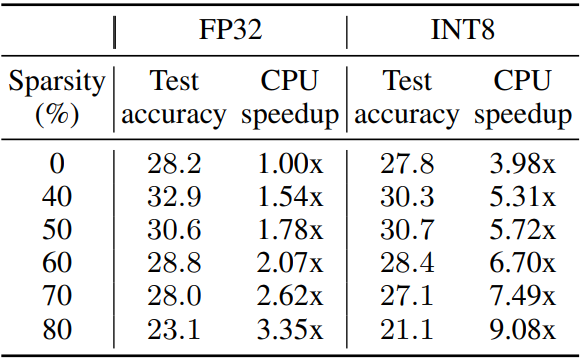
느린 메모리에서 희소 가중치를 압축 형태로 저장하고 빠른 계산에서 압축을 풀어 속도 향상을 얻을 수 있다. (참고)
압축률에 따른 속도 향상:
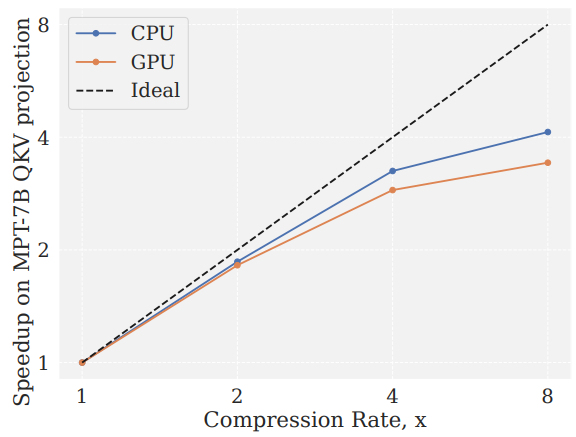
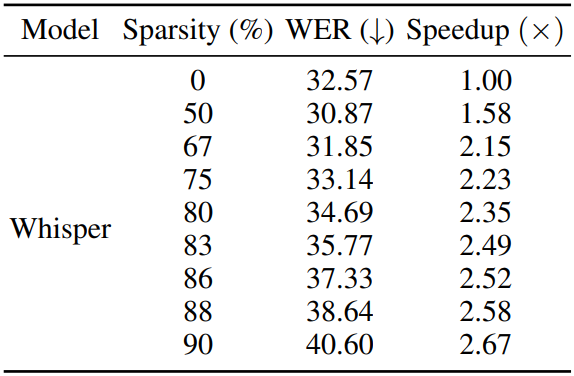
75%의 압축률에서 정확도를 복구할 수 있음.