대규모 이중언어 오픈소스 모델. 훈련 과정을 전부 공개하였다.
[Github]
[arXiv](Current version v2)

Abstract
GPT-3만큼 우수한 이중언어(영어, 중국어)로 pre-training 된 대규모 오픈소스 언어 모델인 GLM-130B 소개.
Introduction
100B의 초대형 모델을 훈련하는 데는 많은 어려움이 있다. 이 분야의 선구자의 GPT-3은 대중에게 투명하게 공개되지 않았다. 이 논문에서는 GLM-130B를 훈련하며 얻은 성공적인 부분, 실패한 옵션 등 훈련 과정을 공개한다.
다른 초대형 모델들과의 차이:

GPT style architecture 대신 General Language Model (GLM) 알고리즘을 채택하였다.
또한 많은 사람들이 LLM 연구를 수행할 수 있도록 단일 A100 서버에서 추론할 수 있는 크기, INT4 양자화를 채택했다.
The Design Choices of GLM-130B
GLM-130B's Architecture
GLM as Backbone
[GLM]은 autoregressive blank infilling을 활용하는 언어 모델이다. 텍스트 시퀀스 x = [x1, ..., xn]에서 text spans {s1, ..., sm}을 샘플링하고 마스크로 대체하여 xcorrupt를 생성하면 모델은 이를 자동회귀적으로 복구하도록 훈련된다.
GLM mask token의 종류:
- [MASK] : 문장 중간의 짧은 공백
- [gMASK] : 제공된 context와 함께 문장 끝의 긴 공백
xcorrupt의 마스크 되지 않은 부분에 대해서는 양방향 attention을 활용한다.

Layer Normalization
레이어 정규화로 DeepNorm 사용.
요약: Post-LN의 불안정성은 훈련 초기의 너무 큰 gradient update로 인해 발생하며 가중치 초기화와 잔차 연결 스케일링을 통해 이를 완화함.
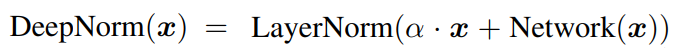

Positional Encoding and FFNs
회전 행렬로 위치 정보를 인코딩하는 PoPE(Rotary Position Embedding),
GeLU 활성화가 포함된 GLU(Gated Linear Unit) 사용.
GLM-130B’s Pre-Training Setup
Self-Supervised Blank Infilling (95% tokens)
영어와 중국어로 구성된 각 시퀀스에 대해 30%는 [MASK], 70%는 [gMASK]로 훈련된다.
Multi-Task Instruction Pre-Training (MIP, 5% tokens)
FLAN과 같은 논문에서 multi-task 훈련에 대한 중요성을 시사했다. LLM의 원래 기능을 방해하는 것을 방지하기 위해 소량의 토큰에 대해서만 수행한다.
Platform-Aware Parallel Strategies and Model Configurations
대부분의 LLM이 덜 훈련되었다는 Chinchilla의 주장에 따라 최대한 많은 토큰을 처리하도록 훈련되었다.
The 3D Parallel Strategy
파이프라인 병렬로 PipeDream-Flush 사용.
(참고 : NVIDIA - Parallelisms)
파이프라인 병렬 p = 8, 텐서 병렬 t = 4, 데이터 병렬 d = 1
GLM-130B Configurations
FP16 정밀도로 단일 DGX-A100(40G) 노드를 실행할 수 있도록 하는 것을 목표로 함. 모델 크기 130B.
파이프라인 균형을 위해 임베딩이 있는 앞뒤 끝 파이프에서 레이어 제거.
총 transformer layer 수 : 9 x 8 - 2 = 70
샘플 당 고정된 2048개의 시퀀스 길이, 4000억 개 토큰, 처음 2.5% 샘플에서 배치 크기 192 ~ 4224, AdamW.
(참고 : Optimizers - Adam, AdamW)
The Training Stability of GLM-130B
Mixed-Precision
혼합 정밀도 사용.

하지만 종종 불명의 손실 급증에 직면했다.

연구진은 transformer가 확장될 때 문제가 생긴다는 것을 깨닫는 데 몇 달이 걸렸다고 한다.
위에서 언급한 DeepNorm을 사용하여 깊은 레이어에서 값이 커지는 것을 방지.
연구진이 관찰한 또 다른 원인은 모델이 확장됨에 따라 attention score가 커져 FP16의 범위를 초과한다는 것이다.
Attention 계산에서 극값을 빼거나 BF16을 사용하는 해결책이 있지만 GLM-130B에는 적합하지 않았고, BLOOM-176B에서 사용한 임베딩 정규화는 훈련의 안정성을 향상할 수 있지만 zero-shot 성능에 해를 끼친다는 단점이 있다.
Embedding Layer Gradient Shrink (EGS)
Gradient norm은 훈련 붕괴에 대한 좋은 지표가 될 수 있다.
연구진은 초기 훈련에서 임베딩 레이어의 비정상적인 gradient를 발견했다.

이를 해결하기 위해 CogView에서 처음 제안한 gradient shrink 사용.
shrinking factor α에 대해 emb = emb* α + emb.detach()*(1- α).
사실 값은 그대로인데 전달되는 gradient가 축소되어 안정화되는 듯하다.

GLM-130B Inference on RTX 2080 TI
추론 가속화를 위해 Faster Transformer를 활용하고 논문 부록에 있는 여러 가지 계산 최적화를 포함하여 C++에서 구현하는 데 2개월이 걸렸다고 한다.
INT4 Quantization for RTX 3090s/2080s
일반적으로 LLM의 양자화는 가중치와 활성화를 INT8로 양자화하는 것이 관행이다. 그리고 활성화의 이상치는 행렬곱 분해 등으로 처리한다.
하지만 GLM-130B에는 활성화의 이상치가 30% 정도로 매우 많다. 따라서 그러한 대처들이 효율적이지 않고, 활성화는 FP16으로 유지하면서 선형인 가중치만 INT4로 양자화하는 방법을 선택했다.
계산적으로 효율적인 absmax 양자화를 row-wise로 적용한다.


사후 훈련 없이도 FP16 정밀도의 GPT-3보다 성능이 좋다.

분포가 넓을수록 양자화 손실이 더 커지는데, 이를 통해 GPT style인 BLOOM의 INT4 양자화 실패를 설명할 수 있다. GLM은 GPT style보다 분포가 훨씬 더 좁은 경향이 있으며, 이는 양자화 손실을 줄인다.

The Results
Language Modeling
Zero-shot LAMBADA ↑

Pile test-set ↓

Massive Multi-task Language Understanding (MMLU)

Beyond The Imitation Game Benchmark (BIG-Bench)

Chinese Language Understanding Evalution (CLUE)




