채널별 스케일링을 통해 LLM 양자화
[Github]
[arXiv](Current version v5)
Abstract
LLM에 대한 8비트 가중치, 8비트 활성화(W8A8) 양자화를 가능하게 하는 훈련이 필요 없고 정확도를 유지하는 범용 PTQ(훈련 후 양자화) 솔루션인 SmoothQuant 제안
Introduction
양자화를 통해 LLM의 막대한 계산 비용을 줄일 수 있다. 예를 들어 INT8 양자화를 사용하면 FP16에 비해 처리량을 거의 두 배로 늘릴 수 있다. 하지만 LLM의 매우 많은 피라미터로부터 나오는 많은 이상치로 인해 정확도가 크게 떨어진다.
SmoothQuant는 이상치의 존재로 인해 활성화가 가중치보다 양자화하기가 훨씬 더 어렵더라도 토큰들은 채널 전반에 걸쳐 유사한 변형을 나타낸다는 관찰에 의존하여 양자화 난이도를 활성화에서 가중치로 이동시킨다.
(활성화 = 활성화 함수 후 출력)

채널에 걸쳐 평활화를 적용하여 모델을 양자화 친화적으로 만드는 mathematically equivalent per-channel scaling transformation을 제안. 또한 SmoothQuant는 다양한 양자화 방식과 호환된다.
Preliminaries
Quantization
INT8 양자화는 다음과 같이 표현할 수 있다:
( ∆ = 양자화 크기, ⌈⌋ = 반올림, N = 목표 비트, 또한 텐서가 0에서 대칭인 경우로 가정)

위와 같은 양자화기는 이상치를 보존한다.
또한 다음 그림과 같이 각기 다른 양자화 level이 있음.

Review of Quantization Difficulty
활성화는 이상치의 존재 때문에 양자화하기가 어렵다. 하지만 이상치의 특징이 있는데, 같은 채널에 지속적으로 나타난다는 것이다.

그러나, 채널별 활성화 양자화는 높은 처리량에서 실행되는 GEMM 커널이 낮은 처리량을 가진 명령어의 삽입을 허용하지 않아서, 양자화는 행렬 곱셈의 외부 차원을 따라서만 수행될 수 있다고 한다.
SmoothQuant
그래서, 채널별 양자화 대신 활성화 X를 평활화 인자로 나누어 평활화한 후 양자화 할 것을 제안한다.
수학적 동등성을 위해 역연산 추가.

평활화 인자 s는 migration strength α(본 논문에서 0.5)와 입력값에 따라 조절됨.


Applying SmoothQuant to Transformer blocks

Attention layer의 선형 계산, BMM(batched matmul) 등 계산량이 많은 연산의 입력 활성화에 평활화를 적용하고 W8A8 양자화.
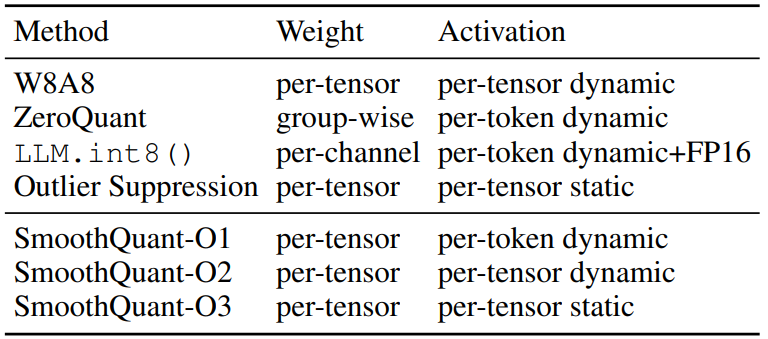
Experiments
Baseline