LLM에 입력되는 feature 자체에 대한 연구, 계층과 모델에 대한 통합 feature 사용
[Github]
[arXiv](Current version v1)

Abstract
Multi-modal Large Language Model(MLLM) 내의 다양한 비전 인코더의 효율성에 대한 광범위한 조사를 수행한다.
관찰을 바탕으로 multi-level feature merging과 함께 DINOv2와 CLIP의 시각적 임베딩을 융합하는 COMM 제안.
Introduction
대부분의 기존 MLLM은 CLIP 또는 그 변형인 EVA-CLIP을 시각적 분기로 사용한다.
CLIP의 visual encoder는 단어 임베딩 공간과 잘 정렬되어 있지만 자세한 픽셀 수준 정보는 학습하지 못해 MLLM의 세밀한 인식 능력에 비해 상당히 불균형하다.
다양한 visual encoder에 대한 광범위한 조사를 통해 얕고 깊은 layer feature에 대한 특징을 알아내고 이를 활용하기 위한 multi-level feature merging를 제안한다.
또한 DINOv2와 CLIP을 융합하는 COMM을 제안한다.
Analysis of The Visual Branch in MLLMs
ViT의 각 레이어에서 추출된 feature를 LLM에 입력했을 때 레이어 깊이별 참조 표현 이해(REC), 참조 표현 생성(REG), 객체 환각 벤치마크(POPE)에 대한 정확도
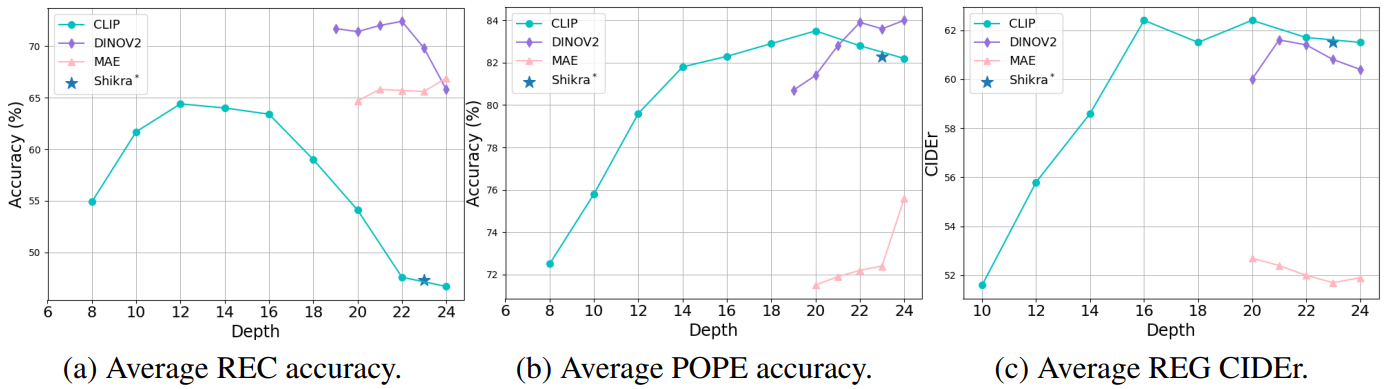
결과적으로 특정 feature에 의존하기보다 shallow, deep feature를 통합하는 것이 성능 향상에 중요하다.
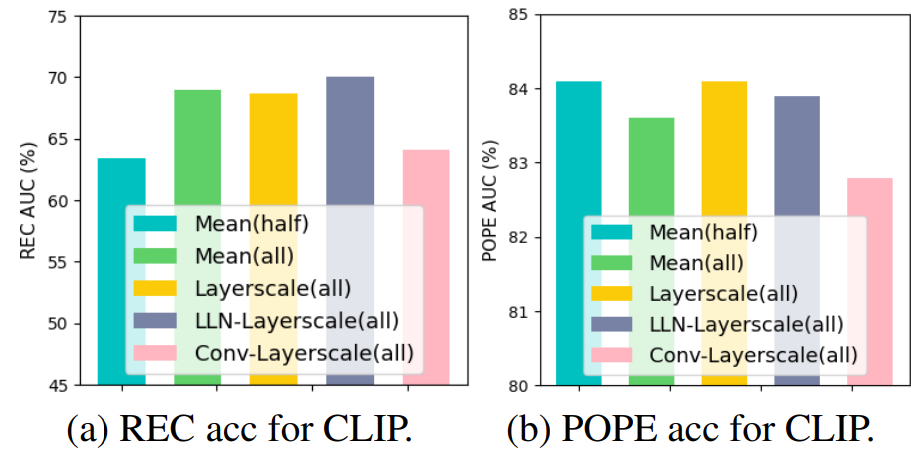
Mutl-ifeature merging (MFM) 방법에 대한 탐구:
ViT의 N개의 transformer layer의 출력을 다음과 같이 표시하면 [z1,..., zi,..., zN]
- Mean(half): N/2 ~ N까지의 z의 평균
- Mean: 모든 z의 평균
- Layerscale: 모든 z에 대해 합이 1인 가중치를 부여 (z = w1z1 + ... + wNzN)
- LLN-Layerscale: 모든 z에 대해 linear-layernorm을 적용한 다음 가중합 (z = w1LLN(z1) + ... + wNLLN(zN))
- Conv-Layerscale: (z = w1Conv(z1) + ... + wNConv(zN))
DINOv2에 MFM 적용:
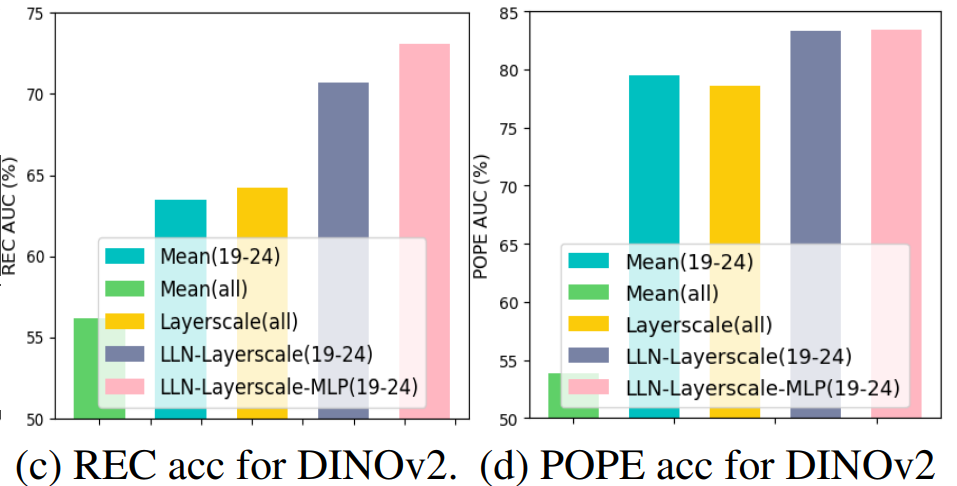
DINOv2에서는 얕은 계층의 feature를 혼합 시 성능이 떨어짐. 또한 MLP를 도입했을 때 성능 향상.
MAE(Masked AutoEncoder), DeiT는 DINOv2보다 훨씬 뒤떨어지는 성능.
COMM: Combining CLIP and DINO with Multi-Level Feature Merging
LLM은 Vicuna.

CLIP은 모든 계층에서, DINOv2는 깊은 계층의 feature에만 liner-layernorm을 적용하고 merging.

Experiments
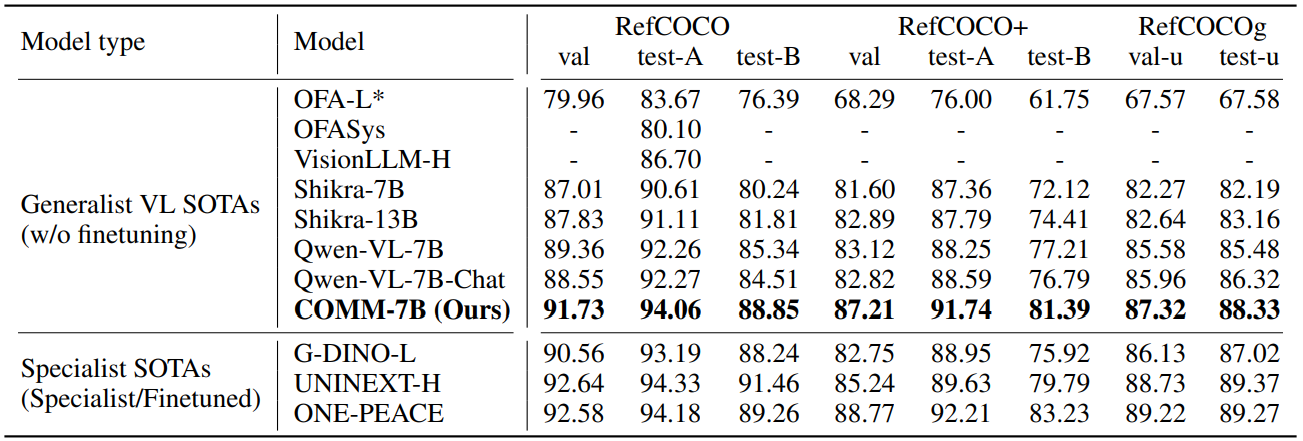
REC
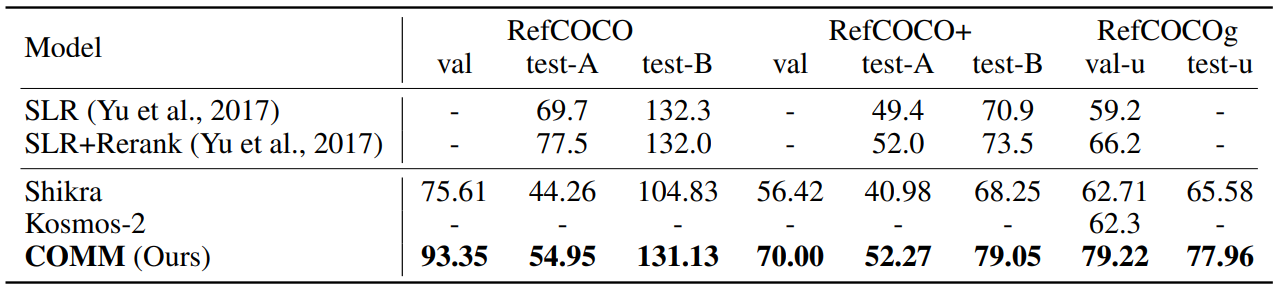
REG
POPE

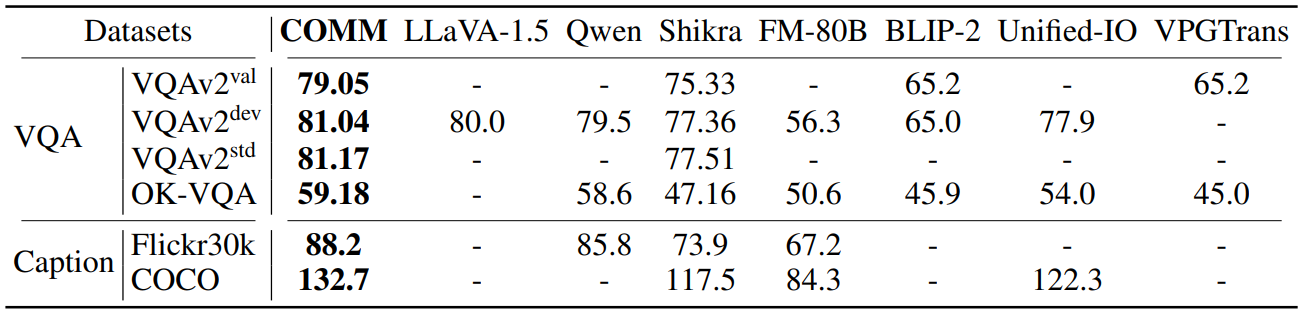
Visual question answering (VQA)