채널별 scaling vector를 학습 가능하게 함
SmoothQuant와의 차이는 이것밖에 없는 듯
[Github]
[arXiv](Current version v1)
Abstract
LLM(Large Language Model)에서 낮은 정밀도 양자화를 활용하면서 모델 출력의 FP32 정밀도를 유지하는 훈련 가능한 등가 변환인 TEQ 제안
Introduction
일반적인 양자화 방법은 두 가지 범주로 나눌 수 있다.

QAT는 매우 많은 피라미터를 가진 LLM에 적합하지 않고, PTQ는 정확도가 매우 떨어지는 단점이 있다.
모델 출력의 수학적 등가성을 FP32 정밀도로 유지하는 학습 가능한 등가 변환을 도입하여 압축 오류를 줄인다.
원래 모델의 0.1% 미만의 훈련 가능한 피라미터로 빠르게 훈련된다.
또한 이러한 방법은 널리 사용되는 LLM 양자화 방법들과 직교하여, 이들과 결합해 더 나은 결과를 얻을 수도 있다.
Methodology
일반적인 matmul 연산을 고려해 보자.

또한 다음과 같은 양자화 작업을 고려한다. (s = scale parameter, [] = 반올림)

w 또는 w, x를 양자화할 수 있고 출력을 재구성하기 위해 역 양자화 작업이 필요하다.

양자화 손실:

Trainable Equivalent Transformation
채널별 스케일링 벡터와 역벡터 추가.(수식을 이해하기 위한 참고)
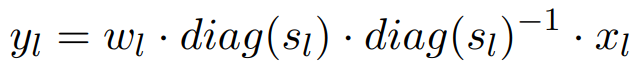
이와 같은 방법으로 양자화 손실을 많이 줄일 수 있기 때문에 PTQ 사용.
가중치 스케일은 가중치 자체에, 활성화 스케일은 norm layer와 같은 이전 레이어에 융합하여 배포 시 추가 오버헤드가 발생하지 않는다고 한다.
Training Details
다음과 같은 양자화 동작을 시뮬레이션하여 스케일링 벡터 sl을 훈련한다.
(SmoothQuant와 유일하게 다른 부분인 듯)

기울기 역전파를 위해 STE 채택.

Experiments





