[Github]
[arXiv](Current version v3)
Abstract
Self-attention의 블록별 계산과 feedforward network의 융합을 활용하여 메모리 비용을 최소화하는 독특한 접근 방식인 BPT(Blockwise Parallel Transformer)를 제안
Blockwise Parallel for Large Context Models
Softmax(QKT)의 전체 행렬을 구하지 않고 입력 시퀀스를 블록으로 분할한 다음 특정 쿼리 블록에 대한 block-wise attention 결과를 스케일링하여 합산할 수 있다. (희소 마스크는 안 쓰는 걸로 보인다. 링크는 그냥 블록별 attention에 대한 예시임)
논문에 수식이 있긴 한데 좀 이상하게 돼있어서 생략함.
이 글 최하단의 코드를 보면 그냥 각 쿼리 블록별로 이 논문에 나온 방식을 KV 블록에 대해 반복하여 attention 값을 구함.
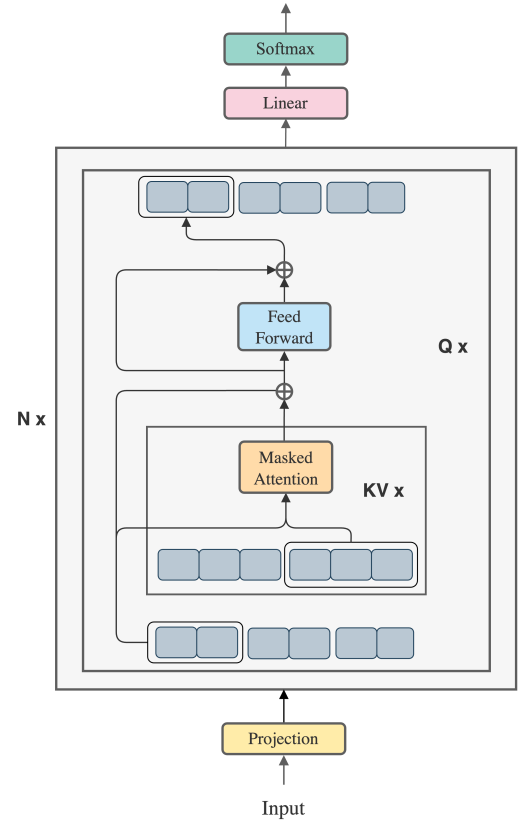
블록별 attention에 FFN과 잔차 연결까지 융합. (하나의 쿼리 블록에 대해 attention + FFN까지 진행)
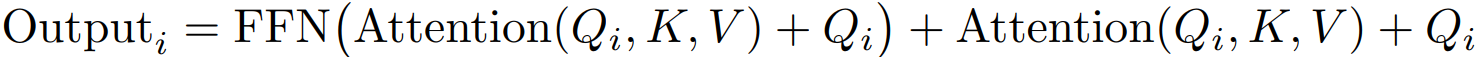

Why Block-wise Parallel
블록 단위 병렬화를 사용하여 통신 비용을 줄이고 처리량을 높일 수 있다.
(장치 하나 당 하나의 쿼리 블록 담당)
나중에 필요할 수도 있을까 봐 올리는 논문 부록의 코드구현