[arXiv](Current version v2)
[BERT]
Abstract
Attention matrix에 희소 블록 구조를 도입하여 장거리 종속성을 더 잘 모델링할 수 있는 가볍고 효율적인 BlockBERT 제안
Introduction
Self-attention이 transformer의 큰 메모리 소비의 주요 원인이다. 하지만 레이어 수, attention head, hidden unit 등을 축소하는 일반적인 방법은 성능을 크게 감소시킨다.
본 논문에서는 희소 블록 구조를 도입하여 이를 해결한다.
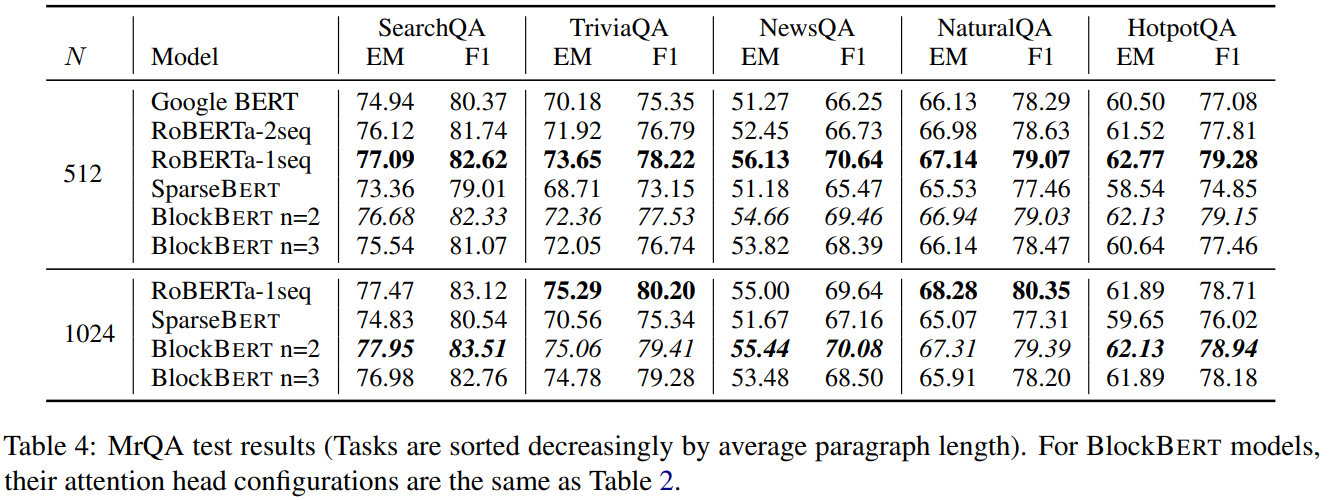
Model: BlockBERT
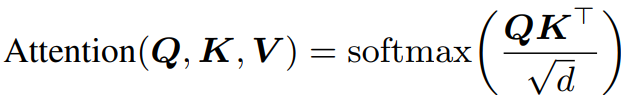
메모리 소모를 줄이기 위한 masked version:
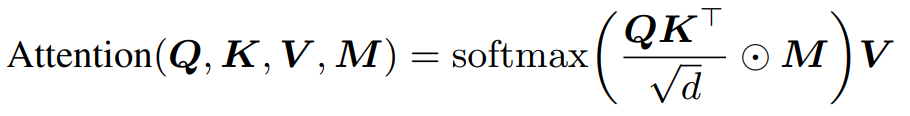
Blockwise Multi-Head Attention
입력 시퀀스 길이 N을 n개의 블록으로 분할, 그러면 attention matrix는 n*n block으로 나뉜다.
순열 π = {1,2,..., n}와 π를 한 칸씩 shift한 각 순열에 대해 마스크를 생성한다. (까만 부분이 1, 하얀 부분이 0)
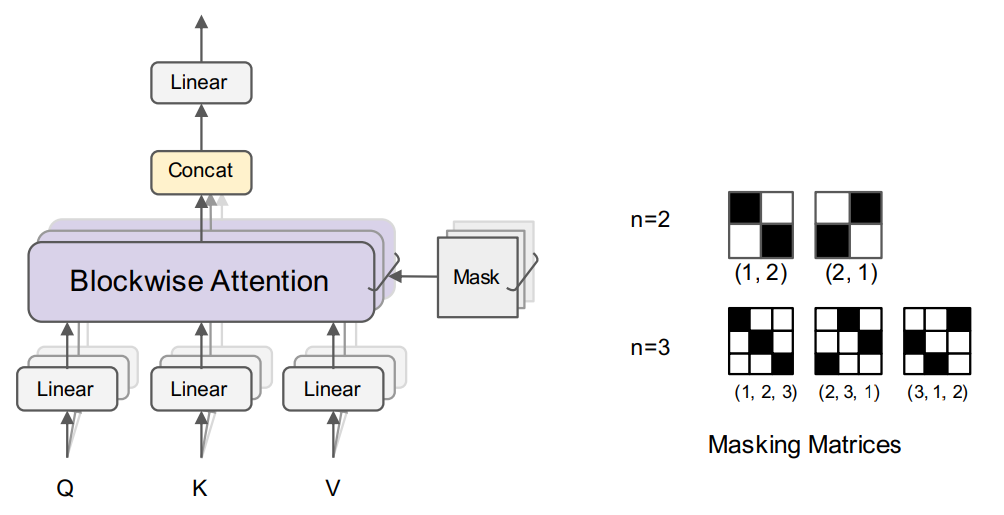
각 attention head에 무작위로 마스크를 할당하고(e.g. (1,2) 마스크에 10 heads, (2,1) 마스크에 2 heads) 각 Q에 대해 각 마스크에서 얻은 K, V에 대한 attention을 수행한다.
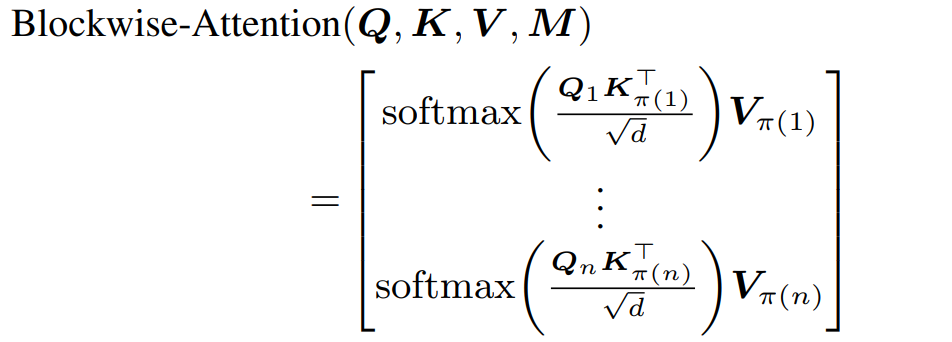

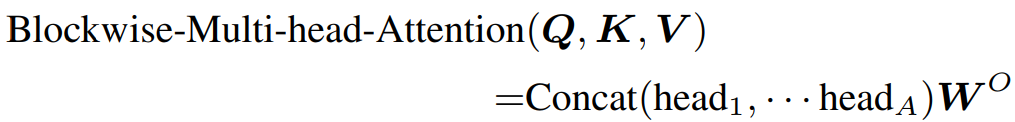
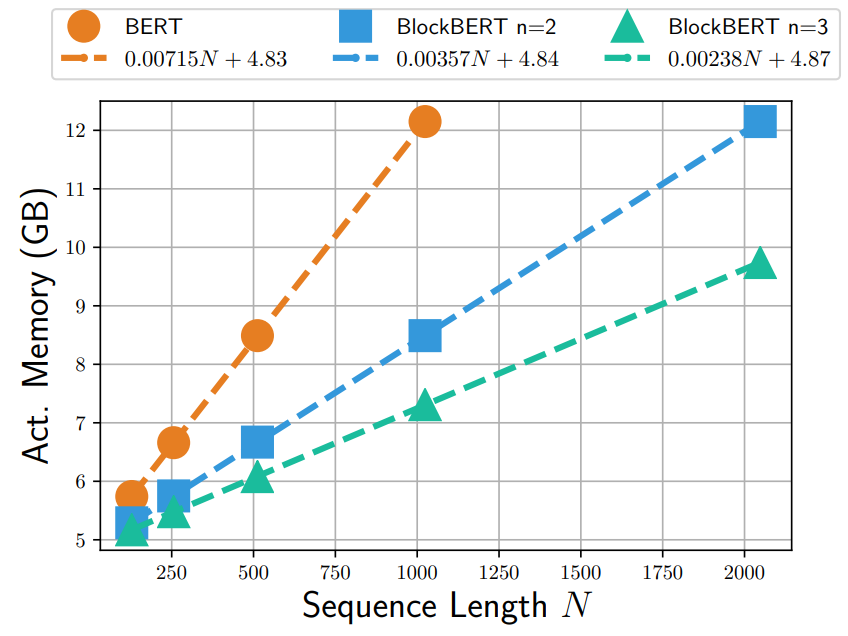
Analysis of Memory Usage Reduction

Experiments