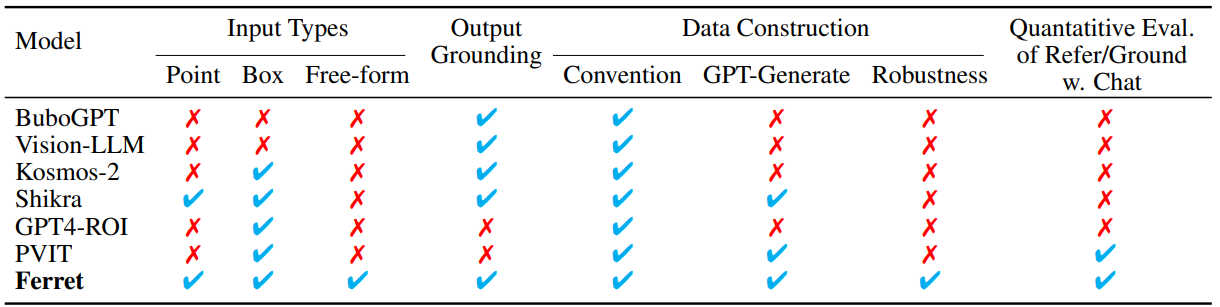
MLLM에서 자유 형식의 영역 입력을 처리할 수 있는 최초의 작업
[arXiv]
[Github]
Abstract
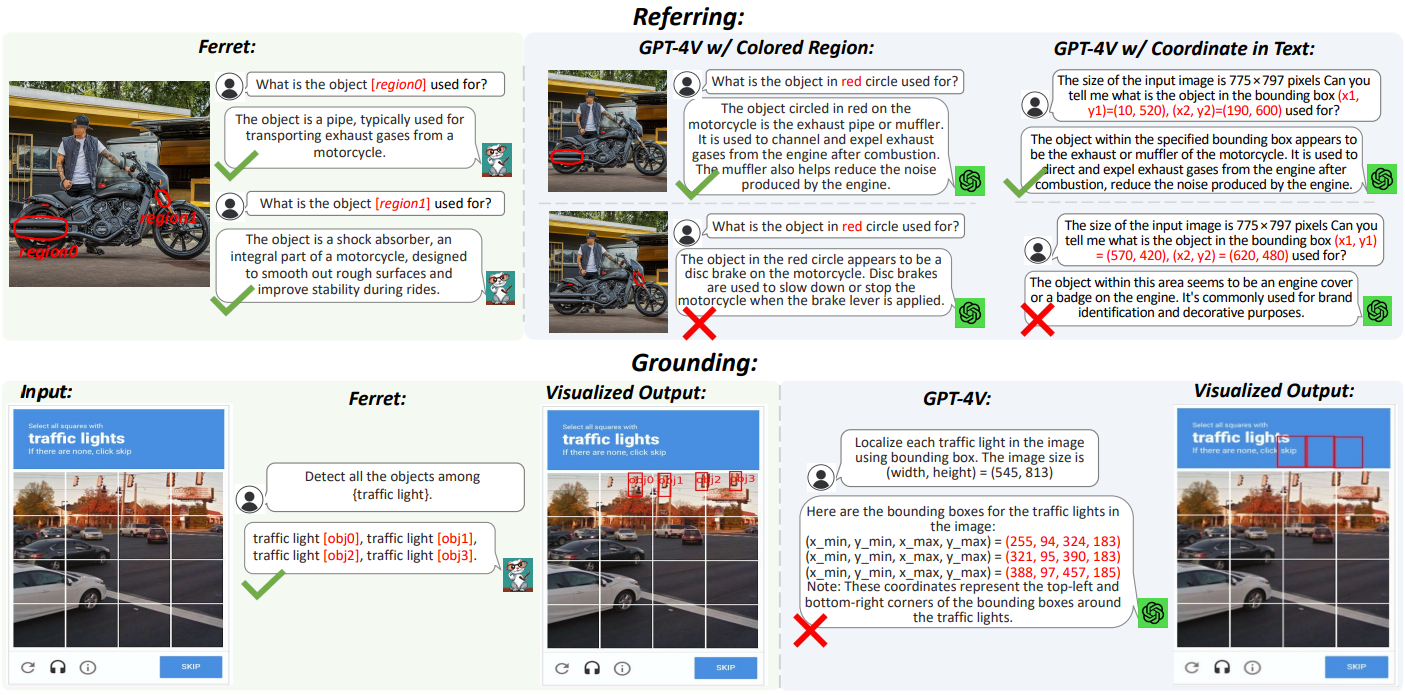
공간 참조를 이해하고 open-vocabulary description을 grounding 할 수 있는 새로운 MLLM(Multi-modal Large Language Model)인 Ferret 소개.
- 다양한 입력을 수용할 수 있는 spatial-aware visual sampler
- GRIT dataset
Introduction
Referring(참조: 영역 → 의미), grounding(접지: 의미 → 영역)
참조와 접지는 본질적으로 공간 정보와 의미의 정렬이 필요함.
Spatial-aware visual sampler를 통해 모든 모양의 영역에 대한 visual feature를 획득할 수 있다.
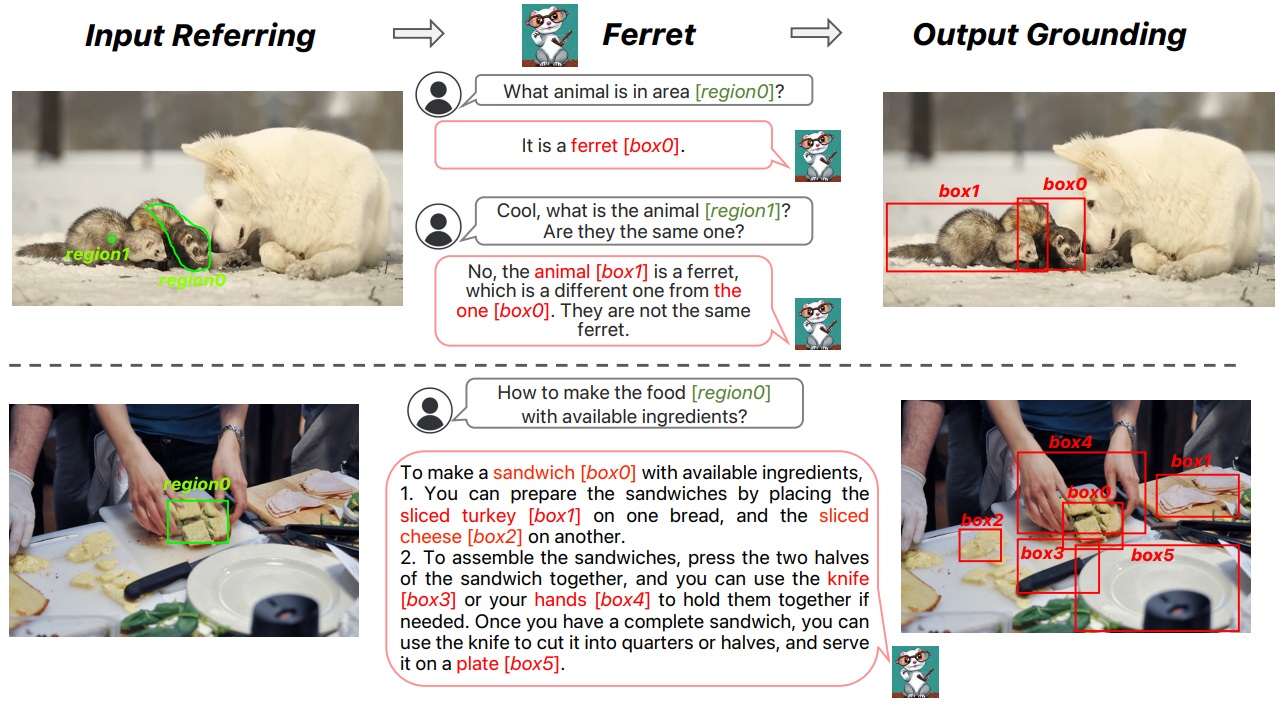
Ferret은 영역과 텍스트의 혼합에 대해 자유롭게 입출력할 수 있으며, MLLM에서 자유 형식의 영역 입력을 처리할 수 있는 최초의 작업이다.
참조 및 접지 기능을 만들기 위한 110만 샘플의 Ground-and-Refer Instruction-Tuning 데이터셋 수집.
또한 참조 및 접지 능력을 평가하기 위한 Ferret-Bench 소개.
Method
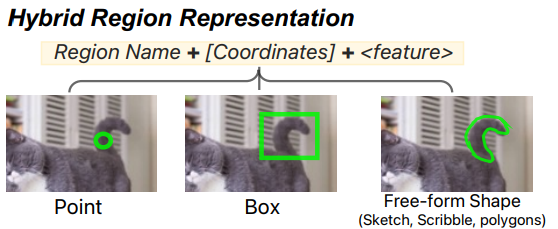
Hybrid region representation
자유형 모양 입력에 대해 내부가 1인 마스크 M으로 만들고 feature map Z와 함께 visual sampler s()에 넣어 f를 얻는다.
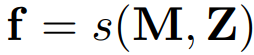
점은 고정된 반경을 가진 원으로 표현:
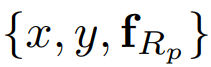
박스와 자유형 모양은 다음과 같이 표현:
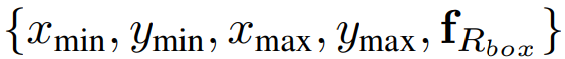
Model architecture
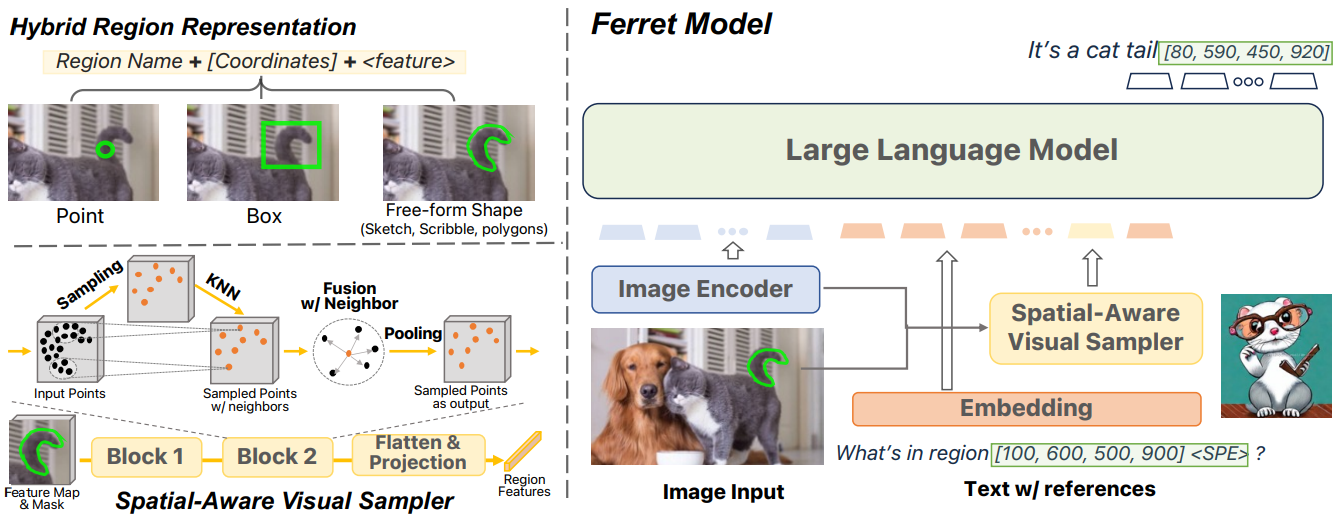
Input
CLIP 이미지 임베딩 Z, LLM tokenizer의 텍스트 임베딩 T,
참조 지역의 경우 (지역 이름, 좌표, SPE token)으로 표시.
Spatial-aware visual sampler
PointNet, PointMLP 등 3D point cloud 처리에서 영감을 얻어 visual sampler 설계.
먼저 마스크 M에서 N개의 점을 무작위로 샘플링한 뒤 3단계 과정을 거침.
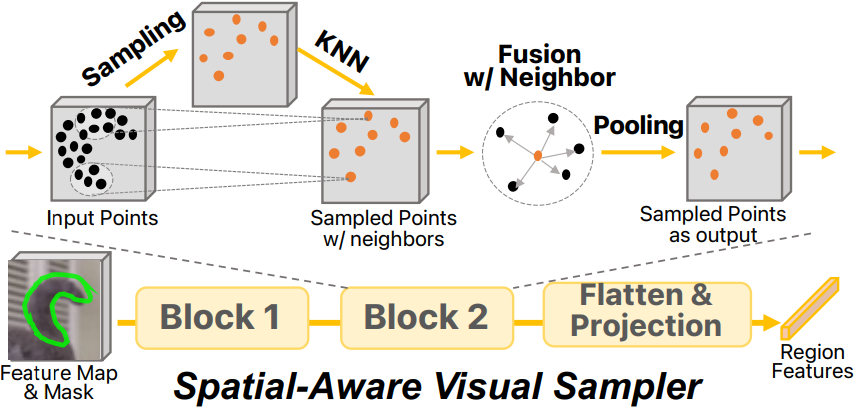
- Sampling : N개의 점에서 FPS(Farthest Point Sampling) 알고리즘을 통해 N/r개의 점 샘플링
- Gathering : 각 점 xi에 대해 원래 N개의 점에서 k개의 이웃 {xik}을 수집하고 각 이웃 지점을 융합
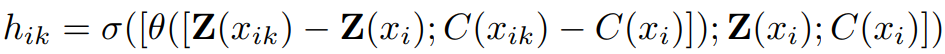
(Z = feature, C = 2D 좌표, θ & σ = 각 정보를 융합하는 linear layer)
- Pooling : Max pooling으로 k개의 이웃 feature를 하나의 feature로 융합
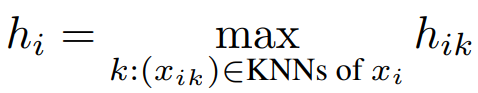
위 과정을 두 번 수행하고 LLM 임베딩 차원에 투영하여 <SPE> 토큰을 대체함.
Output
출력 접지는 해당 지역이나 명사 뒤에 좌표 표시.(e.g. It's a cat tail [80, 590, 450, 920])
LLM
LLM은 Vicuna,
이미지 임베딩을 텍스트 임베딩의 차원과 일치시키기 위해 LLaVA의 projection layer를 사용한다.
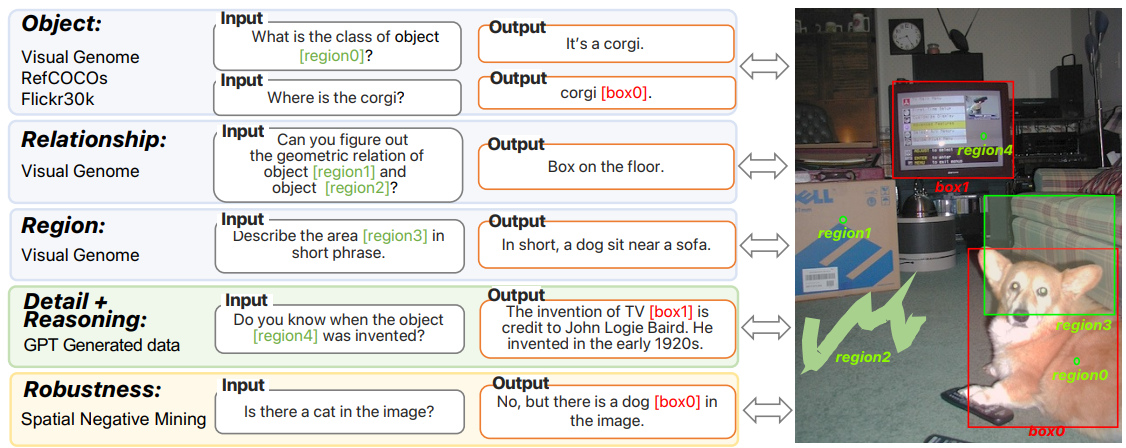
GRIT: Ground-and-Refer Instruction-Tuning dataset
단일 개체, 개체 간의 관계, 지역 설명에 대한 데이터 수집.
또한 해당 데이터에서 SAM을 통해 자유형 모양 데이터 얻음.
ChatGPT/GPT4를 통해 텍스트 장면 설명을 기반으로 instruction tuning data 얻음.
LLaVA-158k 데이터에 open-vocabulary 객체 감지기인 GLIPv2를 적용하여 데이터 얻음.
유사한 속성의 반대 엔티티(e.g. 남자, 여자)와 개체가 위치에 없는 경우에 대한 negative sample mining 수행.
Experiments