Attentoin sink를 이용해 context를 확장하면서 안정성 유지
[arXiv]
[Github]
Abstract
초기 토큰의 Key, Value를 유지하면 window attention 성능이 크게 회복되는 attention sink 현상 관찰.
유한 길이의 LLM을 fine-tuning 없이 무한 길이로 일반화하는 StreamingLLM 소개.
Introduction

(a) 모든 KV(key, value) 캐싱: 계산 비용 부담, 긴 시퀀스 처리 못함.
(b) 최신 토큰의 KV만 캐싱: 계산 효율적이지만 긴 시퀀스에서 성능이 급격히 저하됨.
(c) 생성된 각 토큰에 대해 최근 토큰의 KV 상태를 다시 빌드: 성능은 좋지만 2차 계산으로 인해 실용적이지 않음.
연구진은 attention score의 대부분이 초기 토큰에 몰려있는 attention sink 현상을 관찰함.

StreamingLLM에서는 초기 토큰들(~4)의 KV를 sliding window와 같이 유지함.
또한 초기 토큰 대신 앞부분에 단일 sink token을 추가하여 학습하는 방법을 보여줌.
StreamingLLM
The failure of window attention and attention sinks

초기 토큰이 제거되었을 때 perplexity가 급격히 증가하는 것이 보임.
Attention score의 대부분을 차지하고 있는 초기 토큰을 제거하면 softmax 함수의 분모의 대부분이 제거되기 때문이다.
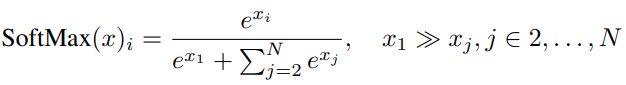
연구진은 초기 4개의 토큰을 linebreak '\n' 토큰으로 바꾼 뒤 실험을 수행했는데, 여전히 똑같은 현상이 일어났다고 한다.
이는 초기 토큰들의 의미보다 절대적인 위치 자체가 이러한 현상을 일으킨다는 것을 의미한다.
연구진의 가설에 의하면, softmax 함수의 특성으로 인해 현재 쿼리가 다른 KV와 연관이 없더라도 반드시 어딘가에 score를 할당해야 하는데, 모든 후속 토큰에 표시되는 초기 토큰들에 이를 할당하는 경향이 있다는 것이다.
일관성을 위해, 모든 훈련 샘플에 초기 토큰 대신 sink 역할을 수행할 sink token을 추가하는 실험도 진행.
Rolling KV cache with attention sinks

StreamingLLM에서 위치 정보를 추가할 때 원본 텍스트의 위치가 아닌 캐시 내의 위치에 대해 추가함.
9번째 토큰을 디코딩하는 중일 때, 위치 인코딩은 [0,1,2,3,6,7,8,9]가 아니라 [0,1,2,3,4,5,6,7]이 됨.
Pre-training LLMs with attention sinks
Attention sink를 완화하기 위한 방법으로 두 가지가 있다.
Softmax-off-by-one은 수정된 softmax 공식으로 모든 attention score의 합이 1이 되도록 강제하지 않는 것이다.
(KV가 0인 sink token을 사용하는 것과 같다고 하여 zero sink라고 부름.)

또 다른 방법은 맨 앞에 불필요한 attention score의 저장소 역할을 하는 sink token을 추가하는 것이다.

Experiments




