[Github]
[arXiv](2024/02/16 version v1)
Abstract
In-Context Learning 능력을 증폭시키기 위한 Linear Transformer Kernel 설계
Background
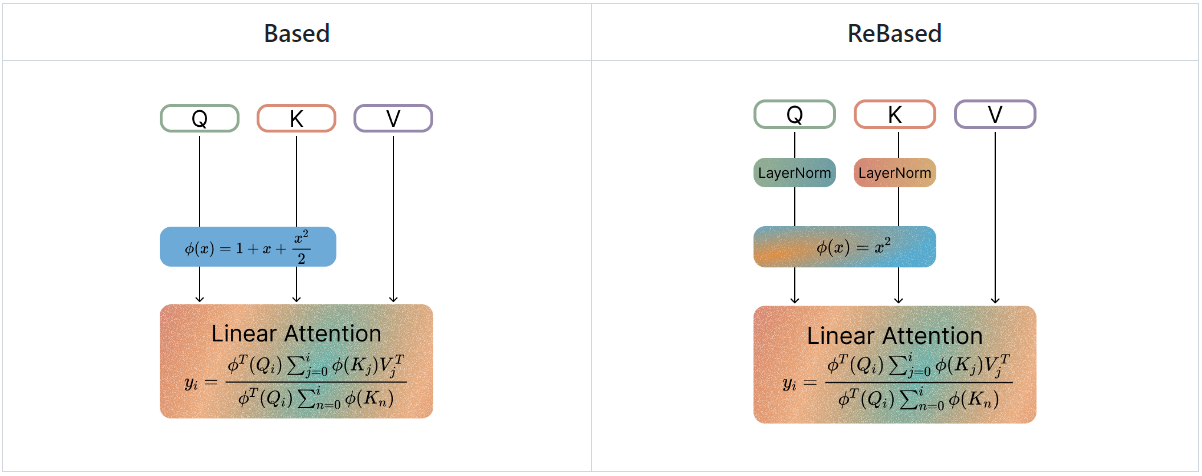
Linear Transformers
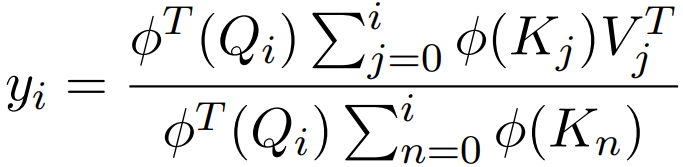
Based
적절한 커널 함수 ϕ의 선택은 중요하다.
Zoology에서는 지수 함수의 Taylor series expansion에서 영감을 받은 커널 함수와
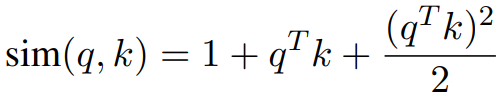
convolution-attention hybrid architecture를 활용한 Based model을 제안하였다.
(근데 막상 Zoology 논문에 저런 커널 얘기는 없는디?)
Revisiting Based
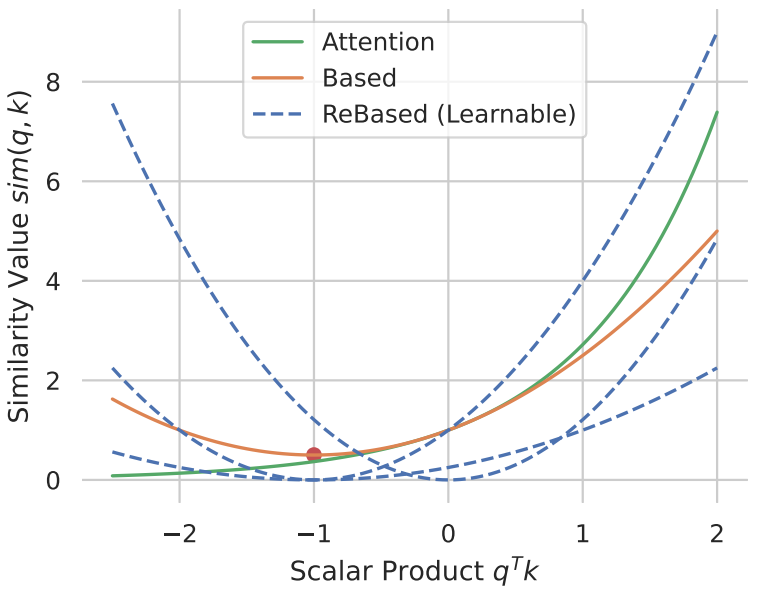
Based 커널은 최솟값이 고정되어 있어 attention score를 0으로 줄일 수 없으며 항상 qk = -1 일 때만 최솟값을 가져야 할 이유도 없다.
따라서 커널에 아핀 변환을 추가하고

이를 통해 ϕ(q')가 최솟값이 0인 모든 이차 함수를 표현할 수 있게 됐으므로 ϕ(x)를 단순화할 수 있다.

최종적으로:
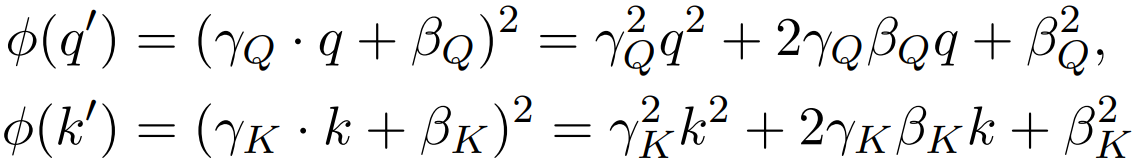
추가로 아핀 변환 전에 LayerNorm을 적용하면 성능이 향상되었다.
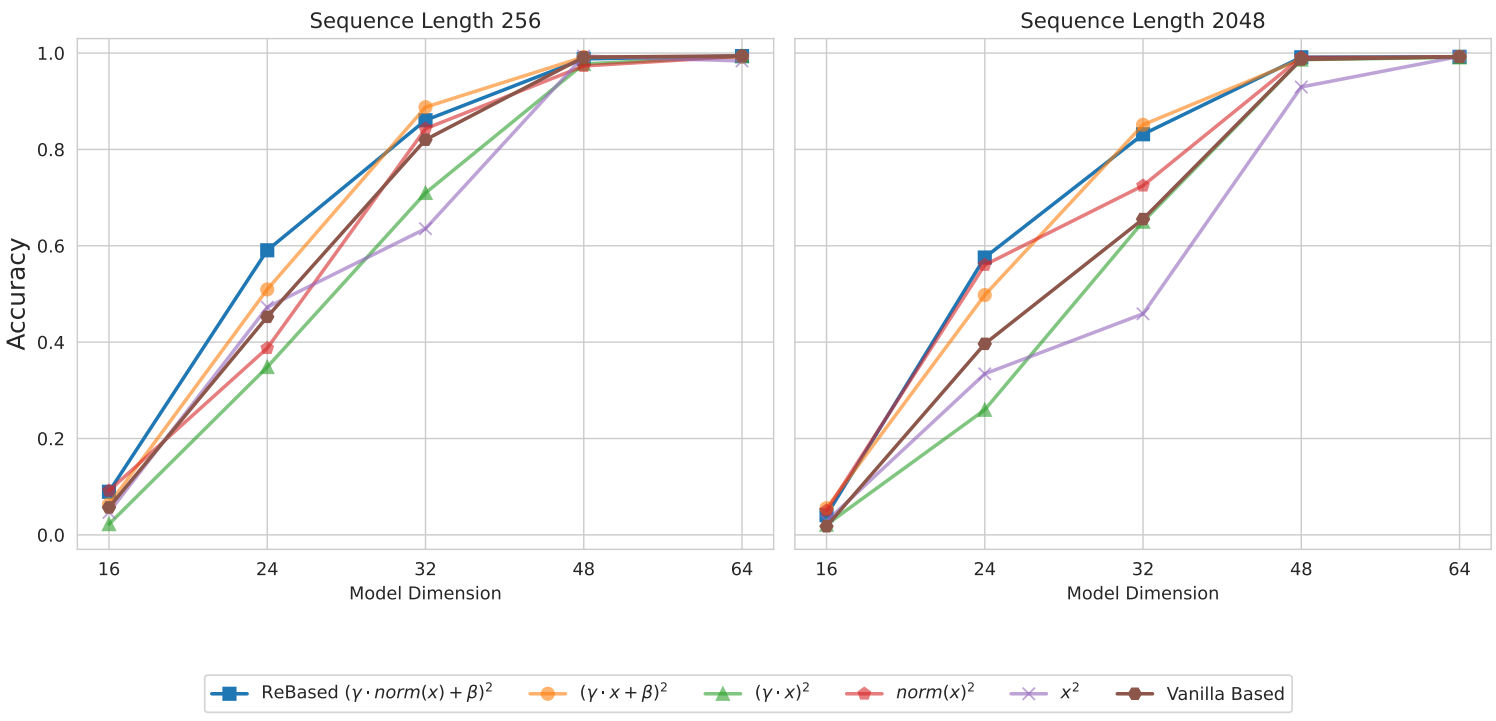
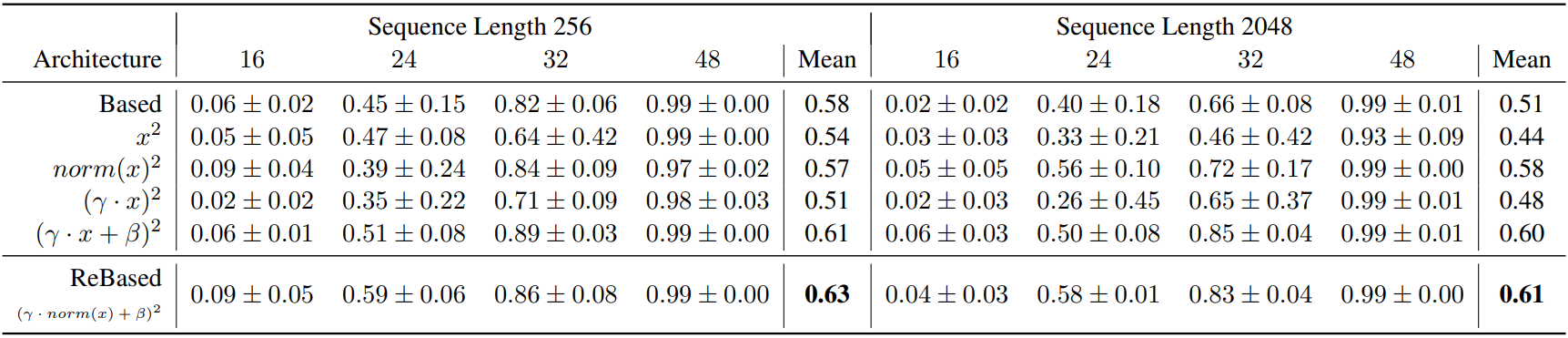
Experiments
Zoology에서 소개된 Multi-Query Associative Recall (MQAR) 작업에 대해 평가함.

Ablation