[Github]
[arXiv](Current version v1)
 |
 |
Abstract
정확한 depth map을 생성하는 것은 어려운 일이다. 일반화된 깊이 조절을 가능하게 하는 LooseControl 소개
Problem Setup - LooseControl
ControlNet의 깊이 제어는 다음과 같이 depth map D가 주어지면 생성 이미지 I를 깊이 추정기 f에 입력했을 때 D와 같도록 한다.
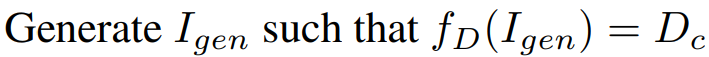
본문에서는 여기에 condition function ϕ를 추가한다.

Scene boundary control
조건 D가 깊이의 상한만 지정하도록 함

3D box control
생성된 객체 O가 경계 상자 B를 준수하는지 확인하는 조건 함수를 설계한다.
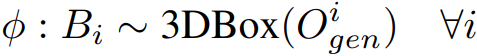

Realizing LooseControl
D의 대한 요구사항:
- ControlNet과의 호환성
- 수동 주석 없이 이미지에서 추출할 수 있어야 함
- 사용자가 수동으로 쉽게 구성할 수 있어야 함
How to represent scenes as boundaries?

먼저 기성 monocular depth estimator를 사용하여 depth map을 추정한 다음 3D triangular mesh로 역투영하고 직교 투영을 사용하여 수평면에 투영한다. 그런 다음 수평면을 다각형으로 근사하고 벽을 돌출시키고 원본 카메라 view에서 깊이를 렌더링하여 depth map D를 얻는다.
How to represent scenes as 3D boxes?

먼저 위와 같은 depth estimator와 SAM을 사용하여 depth map과 segmentation map을 얻는다. 각 image segment에 대해 depth map을 사용하여 3D point cloud로 역투영한 뒤 최소한의 부피로 3D 경계 상자를 추정하고 직육면체 mesh로 표현한다. 그런 다음 역투영에 사용된 원본 카메라 피라미터를 사용하여 box scene을 렌더링하고 depth map을 추출한다.
How to train for LooseControl?
사전 훈련된 ControlNet의 모든 attention block에 대해 LoRA를 fine-tuning 한다.

언급한 모든 과정에 대해 NYU-Depth-v2 dataset과 BLIPv2 캡션 모델이 사용되었다.
Inference time adjustments
추론 시 LoRA scaling factor γ를 도입했다. default γ = 1.2

3D Box Editing

위 움짤과 같이 사용자가 편집을 수행하는 동안 스타일을 유지하기 위해, Text2Video-Zero에서 영감을 받아 attention 도중 K, V를 source image의 K, V로 대체한다. 하지만 U-Net의 모든 레이어를 대체하면 source와 거의 동일한 이미지만 생성되기 때문에 세부사항을 생성하는 마지막 2개의 디코더 레이어에만 적용한다.
Attribute Editing

ControlNet은 위 그림과 같이 U-Net의 bottleneck(h-space)과 디코더 레이어에 잔차를 추가하는데, 이전 연구를 통해 조건 준수에 중추적인 역할을 하는 것으로 알려진 h-space에 초점을 맞춘다.
주어진 고정 조건에서 ControlNet jacobian ∂∆h/∂x의 특이값 분해를 사용하여 가장 영향력 있는 N개의 방향 e를 추출하면 기존의 컨디셔닝 방법으로 어려웠던 다양한 사용자 제어가 가능하다.

Results
LooseControl
Lifting ControlNet for Generalized Depth Conditioning
shariqfarooq123.github.io



