[arXiv](Current version v1)

Abstract
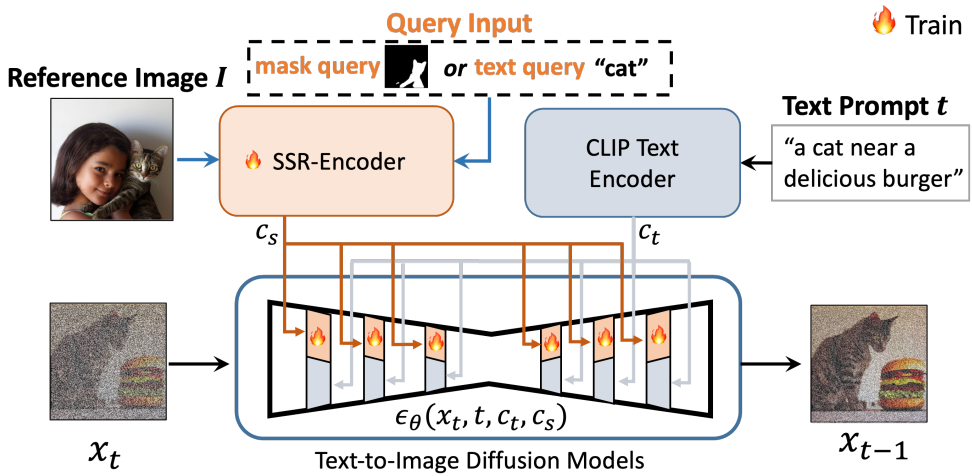
다양한 query modality에 대응하여 참조 이미지에서 피사체를 선택적으로 캡처할 수 있도록 설계된 SSR-Encoder 소개
The Proposed Method
1. Selective Subject Representation Encoder
- Token-to-patch aligner
- Detail-preserving subject encoder
2. Subject Conditioned Generation
3. Model Training and Inference
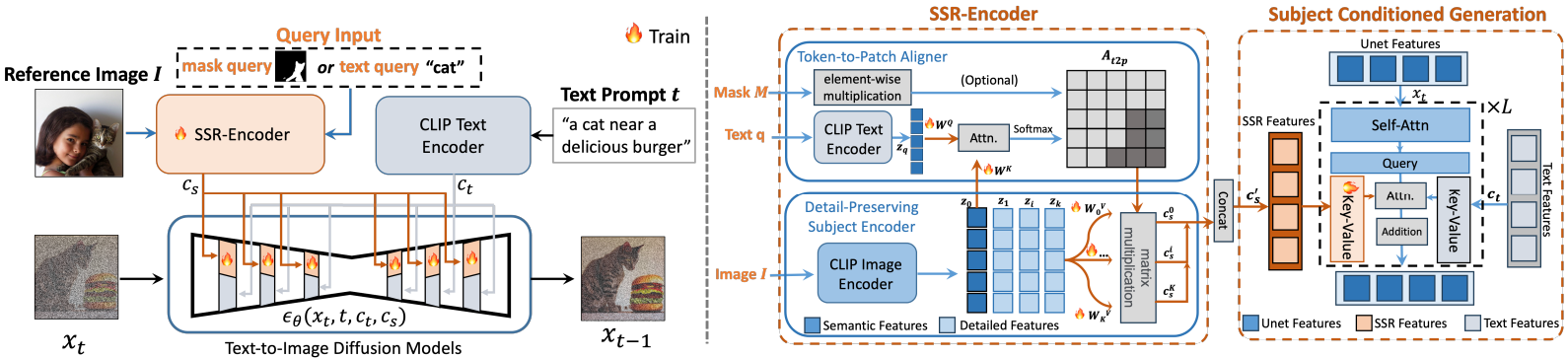
Selective Subject Representation Encoder

Token-to-patch aligner
CLIP은 전경보다 배경을 우선시하는 경향이 있다. Aligner를 통해 text-image feature를 정렬한다.

Token-to-patch attention map At2p는 유사도 식별과 영역 선택의 용도로 사용되며 attention mask를 할당할 수 있다.
Detail-preserving subject encoder
CLIP 최종 레이어의 feature는 디테일이 많이 손실된다. 따라서 다양한 레이어에서 k개의 feature를 추가로 추출하고 표현의 이점을 최대한 살리기 위해 별도의 projection Wk를 적용 후 At2p와 결합하여 subject embedding을 계산한다.

Subject Conditioned Generation

Text condition의 cross-attention과 독립적으로 해당 레이어의 학습 가능한 복사본을 사용하여 subject embedding을 집계한다.
토큰 차원에서 모든 subject embedding을 연결한 뒤에 K, V projection layer를 조정하여 condition에 맞게 훈련한다.

Model Training and Inference
Token-to-patch 정렬을 위해 Embedding Consistency Regularization Loss 도입.
Text embedding과 subject embedding's mean의 코사인 유사도:

일반적인 LDM loss:

Total loss function:

Experiment
Laion 5B dataset에서 aesthetic score가 6 이상인 이미지를 선택하고 BLIP2를 활용하여 캡션 지정
총 천만 개의 고품질 text-image pair
Stable Diffusion v1.5
SSR-Encoder
SSR-Encoder: Encoding Selective Subject Representation for Subject-Driven Generation Yuxuan Zhang, Jiaming Liu, Yiren Song, Rui Wang, Hao Tang, Jinpeng Yu, Huaxia Li, Xu Tang, Yao Hu, Han Pan, Zhongliang Jing Shanghai Jiao Tong University, Xiaohongshu Inc.
ssr-encoder.github.io




