[Github]
[arXiv](2023/09/26 version v3)

Abstract
Cross-attention map에 activation을 생성하여 위치를 제어할 수 있는 Directed Diffusion 제안
Method
아래 두 줄은 각각 처음과 마지막 denoising process의 cross-attention map을 보여준다.
Process의 초기에 위치가 확립되며 cross-attention은 명확한 공간적 해석을 갖는다.

Pipeline
LDM(Stable Diffusion) 기반. 영역 정보 R = {B,I}는 bbox B와 해당 bbox에 대한 prompt index I로 구성됨. e.g. I = {2} = "cat"

Cross-Attention Map Guidance
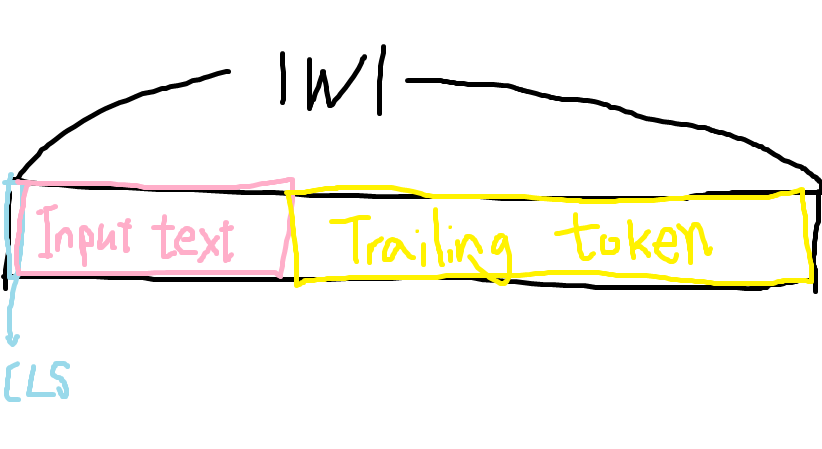
CLIP text encoder의 potential words |W| = 77이다.
Text prompt index i의 cross-attention map은 Ai고, (i ∈ I, 1 ≤ i ≤ |P|)
prompt에 해당하지 않지만 일정한 크기의 행렬 계산을 허용하도록 계산된 나머지 i ∈ T에 대한 attention map은 trailing attention map이라고 한다. T = { |P|+1, · · ·, |W| }
먼저 B가 주어지면 두 가지 함수를 사용하여 modified cross-attention map을 생성한다.

StrengthenMask는 f(본문에서는 Gaussian window)를 사용하여 bbox 내부의 attention을 증가시키고 WeakenMask는 나머지 영역의 attention을 감쇠한다.
Ai(∀i ∈ T ∪ I)에 대해 편집을 적용한 edited map Di는 직접 사용되지 않고 아래의 손실을 최소화하는 vector a를 찾기 위한 최적화 목표로써 활용된다.

여기서 왜 At-1이 사용되는지는 읽어도 잘 모르겠습니다. 기호 표기도 좀 뒤죽박죽인 느낌이고... 결론적으로 위 손실을 이용해 적절한 a를 찾은 뒤 text prompt 부분의 attention map은 편집하지 않고 trailing attention map만 편집하여 다음 step의 추론에 사용된다는 것만 알고 가시면 될 것 같아요...


Cross-attention map의 편집은 초반의 일부 timestep에만 적용된다.

또한 모든 trailing attention map이 사용되는 것은 아니다. 많은 trailing attention map을 사용하면 bbox 영역에서만 feature가 생성된다.

Scene compositing
여러 개체를 생성하려는 경우 각 개체 zt(r)을 개별적으로 생성한 뒤 원래의 프롬프트 P에 대한 latent zt와 선형 보간 후 평균화한다.