[Github]
[arXiv](2023/12/31 version v1)

Abstract
간단한 bounding box를 통해 비디오에서 피사체를 안내할 수 있는 TrailBlazer 제안
Method
깜빡임 없이 고품질 비디오를 생성하는 것으로 유명한(?) VideoFusion의 fine-tuned version인 ZeroScope cerspense를 추가적인 훈련 없이 그대로 사용한다.
VideoFusion은 모든 frame에서 공유하는 base noise와 residual noise를 따로 예측한다.
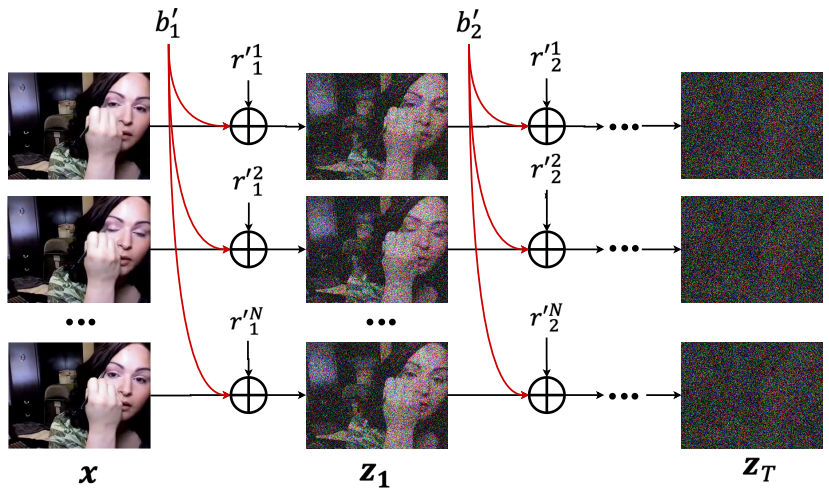
- Pipeline
- Spatial Cross Attention Guidance
- Temporal Cross-Frame Attention Guidance
- Scene compositing
Pipeline

Frame f, f의 bbox 영역 Rf, prompt Pf.
사용자는 시작과 끝을 포함하는 최소 2개 이상의 키프레임에서 R, P를 지정해야 하며, 각 키프레임의 사이는 선형적으로 보간된다.
R = {B, I, T}는 bbox B, subject index I, trailing attention map index T로 구성된다.
- B = bbox(=(left, top, right, bottom)) 내의 모든 픽셀 집합
- “a cat sitting on the car”, I = {1,2} = {"a", "cat"}
- Trailing attention map에 대해서는 Directed Diffusion 참고 (아래부터는 해당 논문에 대한 사전 지식이 있는 것으로 가정합니다.)
Spatial Cross Attention Guidance

i ∈ I∪T에서 spatial attention editing:
(g = Gaussian window, c = scaling factor)

2개 키프레임의 경우 시작 키프레임 Bbeginning, 끝 키프레임 Bend를 보간하여 모든 프레임에 적용한다.

R = {B, I, T}에 대해

Temporal Cross-Frame Attention Guidance

흔히 쓰이는 방법과 같이 시공간축의 차원을 바꾼다.

Temporal attention에 대한 분석을 보면 temporal cross-attention은 프레임 간의 거리가 멀어질수록 전경보다는 주변의 배경에 더 많은 집중을 하는 것을 볼 수 있다.

이것을 모방하기 위해 S를 수정하여 프레임 간 거리가 멀수록 attention score를 낮춘다. 왜 2번 빼는지는 모르겠다.

Temporal cross-frame attention:

Scene compositing
여러 개의 피사체를 생성하려는 경우 Directed Diffusion과 똑같이 각 피사체 zt(r)을 개별적으로 생성한 뒤 원래의 프롬프트 P에 대한 latent zt와 선형 보간 후 평균화한다.


w는 다음과 같이 샘플링 과정에서 점진적으로 증가한다.

Experiments
ZeroScope cerspense를 base로 Diffusers TextToVideoSDPipeline을 override하여 구현.
40 denoising step 중 초반 5 step에 대해 수행.
cm = 0.001, cs = 0.1.
Trailing attention map : 10 ≤ |T| ≤ 20.
Temporal attention editing은 여러 해상도에서 수행할 필요가 없기 때문에 mid_block.attentions.0.transformer_blocks.0.attn2 layer에서만 수행.
TrailBlazer: Trajectory Control for Diffusion-Based Video Generation
WIth recent approaches to text-to-video (T2V) generation, achieving controllability in the synthesized video is often a challenge. Typically, this issue is addressed by providing low-level per-frame guidance in the form of edge maps, depth maps, or an exis
hohonu-vicml.github.io



