딱히 특별한 건 없어 보이는데 왜 성능이 좋은 걸까... SD 2.1이 사기인가? 데이터셋이 좋았나?
[Github]
[arXiv](Current version v1)

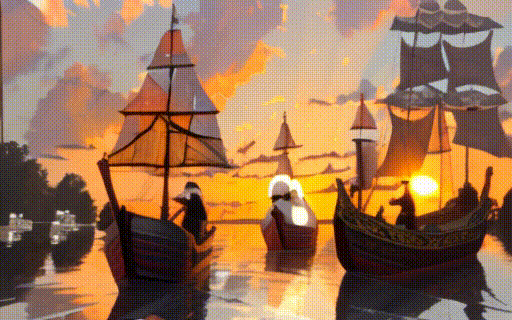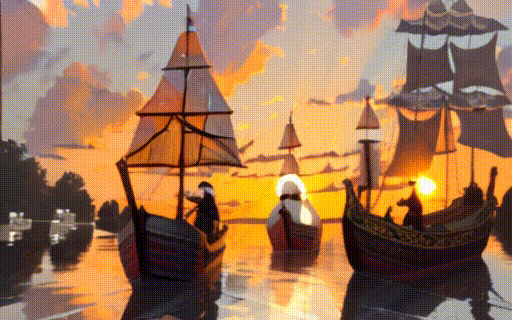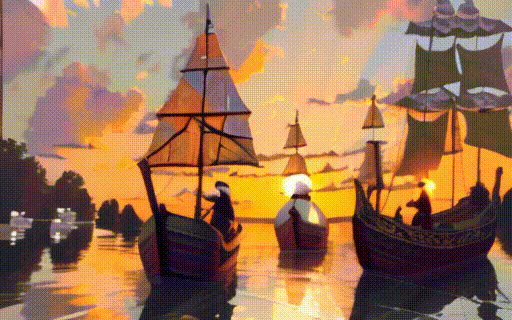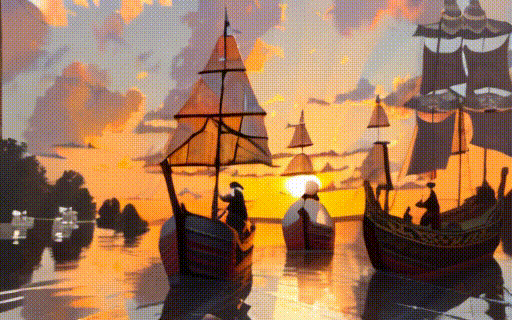
Abstract
1024 × 576 해상도의 고품질 비디오를 생성할 수 있는 T2V, I2V 모델 소개
Introduction
Stable Diffusion 2.1을 기반으로 구축.
- Text-to-Video Model: SD U-Net에 temporal attention layer 통합. 개념 망각을 방지하기 위해 이미지, 비디오 공동 훈련 전략 사용. 2초 길이의 1024 x 576 해상도의 비디오를 생성할 수 있다.
- Image-to-Video Model: 텍스트와 이미지를 모두 입력으로 받을 수 있다. CLIP으로 이미지 추출.
Methodology
VideoCrafter1: Text-to-Video Model
Structure Overview
LDM의 잠재 공간 사용, VDM에 따라 3D convolutoin, temporal attention block 사용.
시간 정보 추출 없이 개별 프레임을 잠재 공간에 투영하고 확산시켜 일련의 video latents zt를 얻음.

Denoising 3D U-Net
Spatial transformers (ST), and temporal transformers (TT).

Cross attention에서 Q는 잠재 토큰이고 K, V는 입력 프롬프트.
fps는 모션 속도를 제어한다.
VideoCrafter1: Image-to-Video Model
Text-Aligned Rich Image Embedding
CLIP 이미지 인코더는 잘 정렬되어 있지만 세부 정보를 캡처하는 능력은 부족하다.
이전 연구들의 vision conditioning 방법에 영감을 받아 CLIP Image ViT 마지막 계층의 full patch visual token을 활용한다.
Projection network를 사용하여 visual token을 임베딩으로 변환하고, 다음 그림과 같이 dual cross-attention을 통해 text, image prompt를 feature에 반영한다. (각 attention에서 query Q는 같다.)

Experiments
Implementation Details
VDM과 같이 이미지, 비디오 공동 훈련.
Stable Diffusion에서 사용되는 해상도를 점진적으로 증가시켜 훈련하는 방법을 사용한다.
256x256, 256 batch, 80k interations → 512x320, 128b, 136k interations → 1024x576, 64b, 45k interations.
I2V 모델의 경우 (T2V에서?)projection network를 훈련한 뒤 비디오 모델 fine-tuning.
Performance Evaluation
VideoCrafter1
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation.
ailab-cvc.github.io
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.



