Style transfer with adapter


Abstract
T2I 모델을 이용하여 특정 스타일을 충실히 따르는 이미지 합성을 가능하게 하는 방법인 StyleDrop 소개.
극소수의 매개변수만을 fine-tuning 하고 반복 훈련을 통해 품질을 개선함으로써 새로운 스타일을 효율적으로 학습.
Introduction

- Transformer-based T2I model : Muse
- Adapter tuning : adapter 형식의 적은 추가 피라미터
- Iterative training with feedback : 과적합 완화, 성능 향상
StyleDrop
Preliminary: Muse
Muse의 구성요소:
Text encoder T,
Visual token logits를 생성하는 transformer G,
Iterative decoding을 사용하는 sampler S,
Encoder E, Decoder D.
텍스트 t가 주어졌을 때 이미지 I는 다음과 같이 생성된다. 그리고 각 디코딩 단계에서 생성되는 로짓 lk (+ CFG).
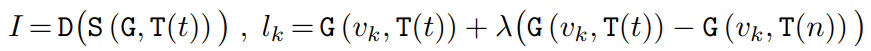
손실함수:

(CE = Cross Entropy, m = mask, M = masking)
Parameter-Efficient Fine-Tuning of Text-to-Image Generative Vision Transformers
본 논문에서 제안하는 프레임워크는 다양한 T2I, T2V 모델과 fine-tuning 방법들에 적용할 수 있지만, Muse와 adapter 기반 튜닝 방법에 중점을 두고 서술한다.
새로운 피라미터 θ를 도입한 transformer Ĝ


(Content-Style 분리를 위한 image-text pair 데이터셋 Dtr 사용)
이미지 생성:
Ĝ은 다른 데이터셋을 사용하기 때문에 텍스트 정렬을 위한 마지막 항 추가.

Constructing Text Prompt
스타일 참조 이미지의 text pair가 없는 경우가 많다. 따라서 그런 이미지들에 간단한 형태의 text prompt 추가.

위와 같은 구체적인 스타일 설명 대신에 토큰 식별자 [v]를 사용할 수도 있지만, 스타일 설명이 더 유연한 속성 편집 가능.

Iterative Training with Feedback
다음과 같은 스타일 이미지에 대해

간혹 콘텐츠 유출이 일어날 수 있다.

간단한 해결책으로, 다음과 같이 합성에 성공한 이미지들로 다시 데이터셋을 만들어 반복적으로 학습하는 것이다.

중요한 것은 합성된 이미지의 품질을 평가하는 방법이다.
- CLIP score : image-text 정렬을 평가할 수 있다. 하지만 인간의 의도와 완벽하게 일치하지 않을 수 있고 미묘한 스타일 차이를 감지하기 어렵다.
- Human feedback : HF로 clip score를 보완할 수 있다. 적은 수의 이미지만 골라내면 되므로 오래 걸리진 않는다.
Sampling from Two θ’s
DreamBooth와 StyleDrop을 결합하여 콘텐츠를 개인화하는 방법.
(DreamBooth를 활용한다는 게 모델을 썼다는 게 아니고 방법을 Muse에 사용한다는 말인 듯하다?, 아니면 그냥 content binding 작업 자체를 dreambooth라고 통칭하는 것 같기도.)
StyleDrop은 style과 content의 공동 훈련이 필요하지 않으므로 θs, θc를 각각 학습하여 다양한 구성을 얻을 수 있다.

(c = 스타일 설명자가 없는 text prompt)

Experiments

HF 작업에 공을 들이고 반복 학습을 할수록 성능이 더 좋아짐.
'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| ProPainter: Improving Propagation and Transformer for Video Inpainting (3) | 2023.10.12 |
|---|---|
| Flow-Guided Transformer for Video Inpainting (FGT) (0) | 2023.10.12 |
| FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting (0) | 2023.10.10 |
| Fast Segment Anything (FastSAM) (1) | 2023.07.14 |
| Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture (I-JEPA) (0) | 2023.07.08 |
| Recognize Anything: A Strong Image Tagging Model (RAM) (0) | 2023.06.19 |



