데이터 증강 없이 의미론적 표현 학습하기
Abstract
Hand-crafted data-augmentation에 의존하지 않고 의미론적인 표현을 학습하기 위한 아키텍처인 I-JEPA 소개.
단일 context block에서 다양한 target block의 표현을 예측한다는 아이디어.
Introduction

I-JEPA의 기본 개념은 추상 표현 공간에서 누락된 정보를 예측하는 것.
I-JEPA는 추상적인 예측 대상을 사용하므로 불필요한 픽셀 수준 세부사항이 무시되어 더 의미론적인 feature를 학습한다.
Method
ViT 아키텍처 사용.
MAE와 비슷하지만 중요한 차이점은 예측이 표현공간에서 이루어진다는 것.
Targets.

입력 이미지를 target encoder fθ̄를 통해 패치 수준 표현(sy)으로 변환하고 패치를 무작위 샘플링한 뒤 스케일링하여 target block 생성.
Context.
이미지 범위를 스케일링하여 context block x와 관련 마스크 Bx 생성.
Target block과 겹치는 부분을 제거하고 context encoder fθ를 통해 패치 수준 표현 sx 얻음.
Prediction.
Predictor는 sx와 예측하고자 하는 마스크 토큰을 입력으로 받고 M개의 예측에서 각각 ŝy 출력.
Loss.
간단한 L2 거리.
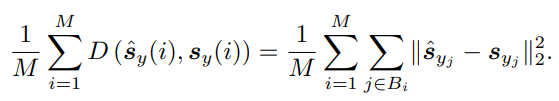
Predictor와 context encoder θ는 gradient 최적화로 학습되고 target encoder θ̄는 θ의 EMA로 업데이트.
'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting (0) | 2023.10.10 |
|---|---|
| StyleDrop: Text-to-Image Generation in Any Style (1) | 2023.09.26 |
| Fast Segment Anything (FastSAM) (1) | 2023.07.14 |
| Recognize Anything: A Strong Image Tagging Model (RAM) (0) | 2023.06.19 |
| Tag2Text: Guiding Vision-Language Model via Image Tagging (0) | 2023.06.19 |
| Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection (0) | 2023.06.19 |



