Abstract
사전 훈련된 확산 모델을 기반으로 추가 훈련 없이 무한히 긴 비디오를 생성할 수 있는 FIFO-Diffusion 제안
[Github]
[arXiv](2024/05/19 version v1)
FIFO-Diffusion
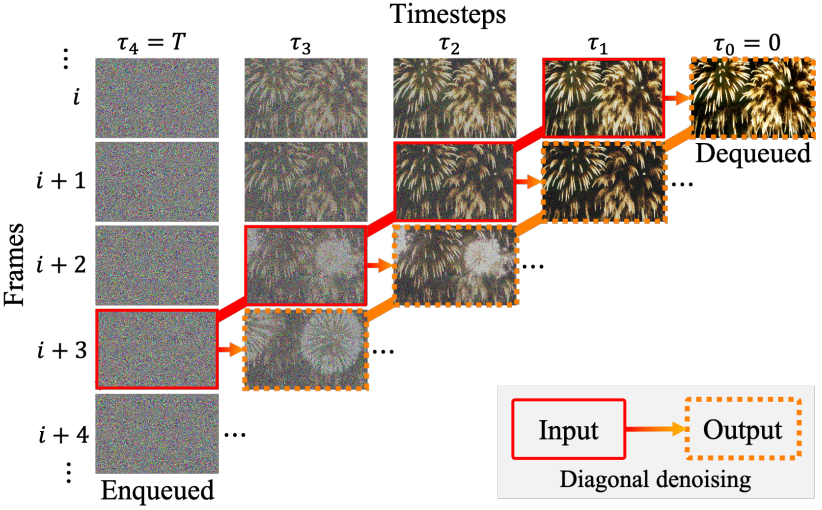
Diagonal denoising
방법은 간단하다. Timestep을 프레임과 같은 f로 나눈 후 다음과 같이 처리한다.
빨간 실선으로 둘러싸인 프레임들이 한 번에 계산되는 프레임들이다.
중요한 것은 기존의 비디오 확산 모델처럼 모든 프레임이 모든 같은 timestep을 공유하지 않는다는 것이다. 프레임 간의 거리는 timestep 간의 거리와 같다.

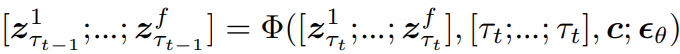

Latent partitioning
원본 확산 모델은 모든 프레임에서 같은 timestep을 예측하도록 훈련되었는데, fine-tuning 없이 다른 timesteps을 가진 이미지들을 예측하게 해도 괜찮을까?
증명과 정리가 와랄랄라 하고 나오지만 생략.
어쨌든 확산 모델 ϵθ가 Lipschitz 연속이라는 가정 하에 FIFO-Diffusion의 오류는 noise level의 차이에 비례해서 선형적으로 제한된다고 한다.

Latent partitioning
이에 따라 timestep을 n배로 확장하고 Queue를 n개의 블럭으로 나누어 계산한다.

- Noise level 차이를 줄임, 많은 추론 단계를 사용하여 오차를 줄일 수 있음
- GPU 병렬 추론을 활용할 수 있음
추론을 시작하려면 nf개의 latent가 필요하다.
확산 모델의 원래 기능을 통해 일단 f개의 프레임을 생성하고 z00을 (n-1)f번 반복 후 노이즈를 추가하여 큐에 넣고 f개 프레임에도 노이즈를 추가하여 큐에 넣는다.
Lookahead denoising
Diagonal denoising은 추론 오차를 유발하지만, 깨끗한 이전 프레임을 볼 수 있다는 장점 또한 있다.
실제로 블럭의 후반 프레임은 손실이 더 낮다. (LP)

이 장점을 더욱 활용하기 위해 블럭을 겹치도록 분할하고 후반 프레임만 업데이트한다.
e.g., 빨간 블럭의 경우 i+7, i+6

Experiment
FIFO-Diffusion
FIFO-Diffusion: Generating Infinite Videos from Text without Training Jihwan Kim*1 Junoh Kang*1 Jinyoung Choi1 Bohyung Han1, 2 NeurIPS 2024 --> 1ECE & 2IPAI, Seoul National University (* Equal Contribution) {kjh26720, junoh.kang, jin0.choi, bhhan}@snu.ac.k
jjihwan.github.io



