
Abstract
잠재 공간에서 작동하는 새로운 증류 손실을 통해 확산 모델을 GAN으로 추출
[arXiv](2024/05/09 version v1)
Method
- Paired Noise-to-Image Translation for One-step Generation
- Ensembled-LatentLPIPS for Latent Space Distillation
- Conditional Diffusion Discriminator
Paired Noise-to-Image Translation for One-step Generation
DDIM sampler를 이용해 ODE 궤적을 시뮬레이션하여 ODE solution, noise 쌍을 얻고 증류 손실을 통해 G를 최적화하는 일반적인 방법.
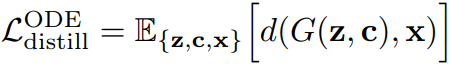
이러한 고전적인 방식은 최신 증류 방법에 비해 성능이 매우 열등하다.
하지만 연구진은 ODE dataset을 확장하고 픽셀 단위 손실 대신 지각 손실을 사용하면 증류 품질이 크게 향상됨을 관찰했으며, Consistency Model 보다도 낮은 FID를 달성했다.
Ensembled-LatentLPIPS for Latent Space Distillation
하지만 픽셀 공간에서 작동하는 LPIPS는 LDM에서 사용하기에 너무 느리다.
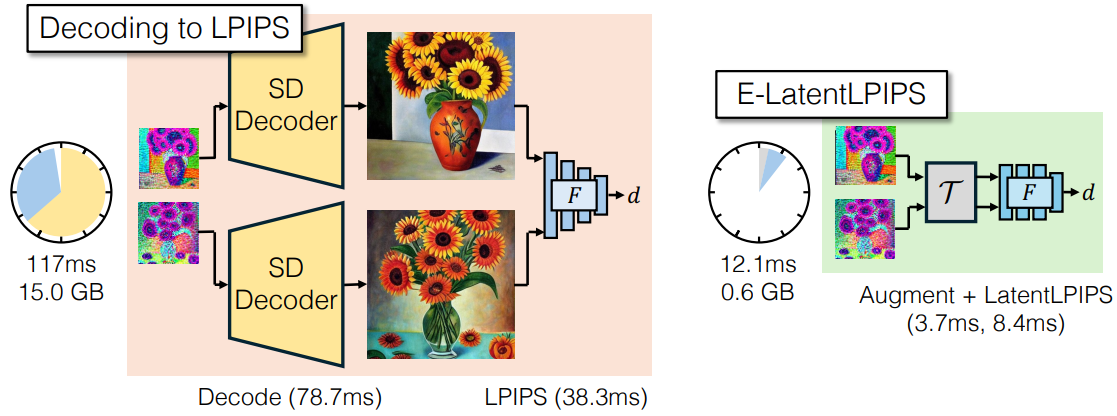
Learning LatentLPIPS
LPIPS의 지각적 특성이 잠재 공간에서도 유지된다는 가정하에 VGG network를 잠재 공간에서도 작동하도록 훈련한다.
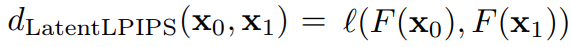
Ensembling
LatentLPIPS를 직접 적용했을 때 훈련이 수렴되지 않음을 관찰했다.

E-LPIPS에서 영감을 받아 미분 가능한 무작위 증강을 양쪽에 모두 적용하였더니 거의 완벽하게 재구성되었다.
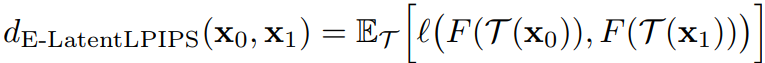

Conditional Diffusion Discriminator
GAN은 확산 모델보다 훨씬 빠르고 controllable 하므로 1-step 모델로 채택하기에 적합하다.
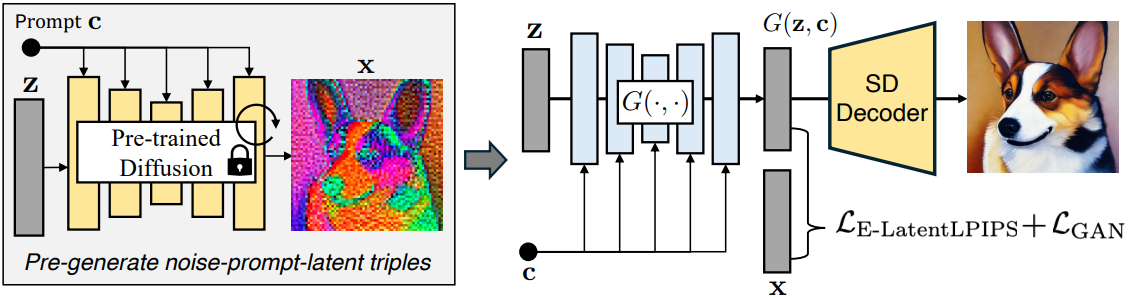
GAN loss로는 일반적인 min-max, non-saturating loss 사용하며 c 뿐만 아니라 z도 GAN에 공급한다.
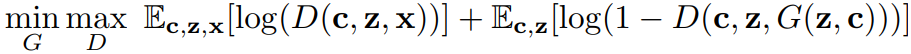
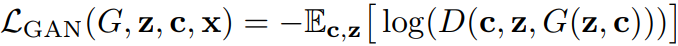
G에 대한 손실:
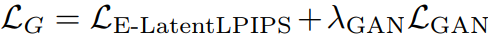
Initialization from a pre-trained diffusion model
판별자로 U-Net을 사용하여 사전 훈련된 확산 모델의 가중치로 초기화한다.
또한 각 다운샘플링 단계에서 각 블록에 입력 이미지를 공급하고 업샘플링 단계의 각 해상도마다 예측을 수행한다.
DDIM은 결정적이기 때문에 단일 conv layer로 처리한 z 또한 입력하고 텍스트 조건은 cross-attention을 통해 주입된다.
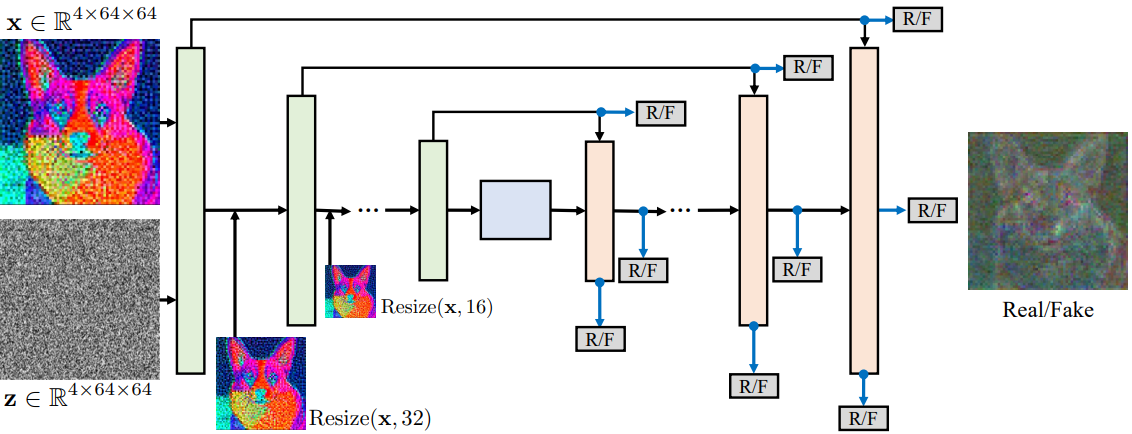
Multi-scale in-and-out U-Net discriminator
업샘플링 단계의 각 해상도에서 1번씩이 아니라 residual feature, upsampled feature, combined feature 총 3번씩 Real/Fake 예측을 수행한다.
Single-sample R1 regularization
D의 수렴에 도움을 주는 R1 regularization을 사용.
그러나 우리는 D로 고용량 U-Net을 사용하기 때문에 추가적인 gradient term을 사용하면 메모리 문제가 발생할 수 있어 각 미니배치의 단일 샘플에만 적용한다.
Mix-and-match augmentation
D는 이미지 x가 조건 c와 얼마나 일치하는지, x가 얼마나 사실적으로 보이는지를 고려하여 판단을 내린다.
하지만 훈련 초기에는 G의 품질이 좋지 않고 아티팩트가 발생하며 이에 따라 D는 c를 고려하지 않은 채 x의 품질에만 의존한 판단을 내리게 된다.
훈련 중 {G(z), c} 쌍의 일부를 c와 관련 없는 x로 대체하여 품질은 좋지만 c와 관련 없는 fake sample을 만든다.
Experiments
Diffusion2GAN for One-step Text-to-Image Synthesis. arXiv2024
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference while preserving image quality. Our approach interprets the diffusion distillation as a paired image-to
mingukkang.github.io
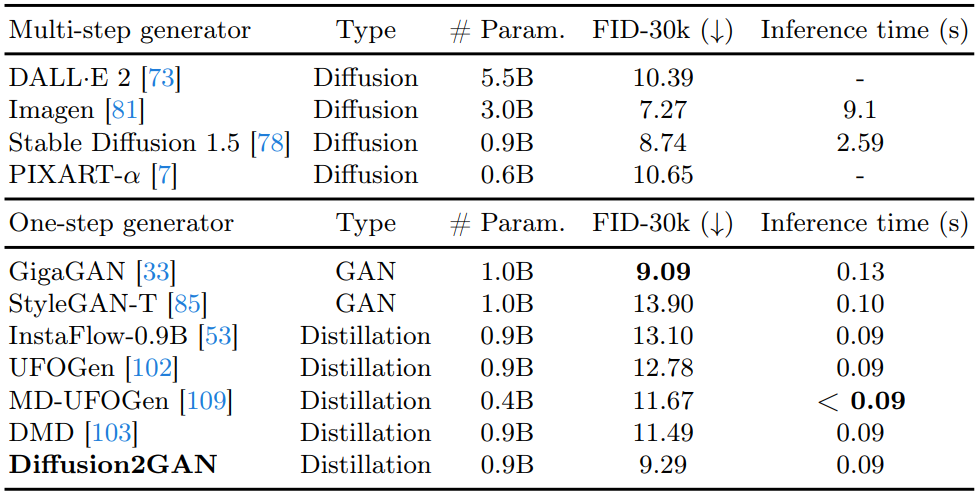
Comparison
Ablation




