[Github]
[arXiv](2023/08/02 version v1)
Abstract
Mixture of Experts의 문제들을 해결하면서 이점을 유지하는 완전 미분 가능한 SoftMoE 제안
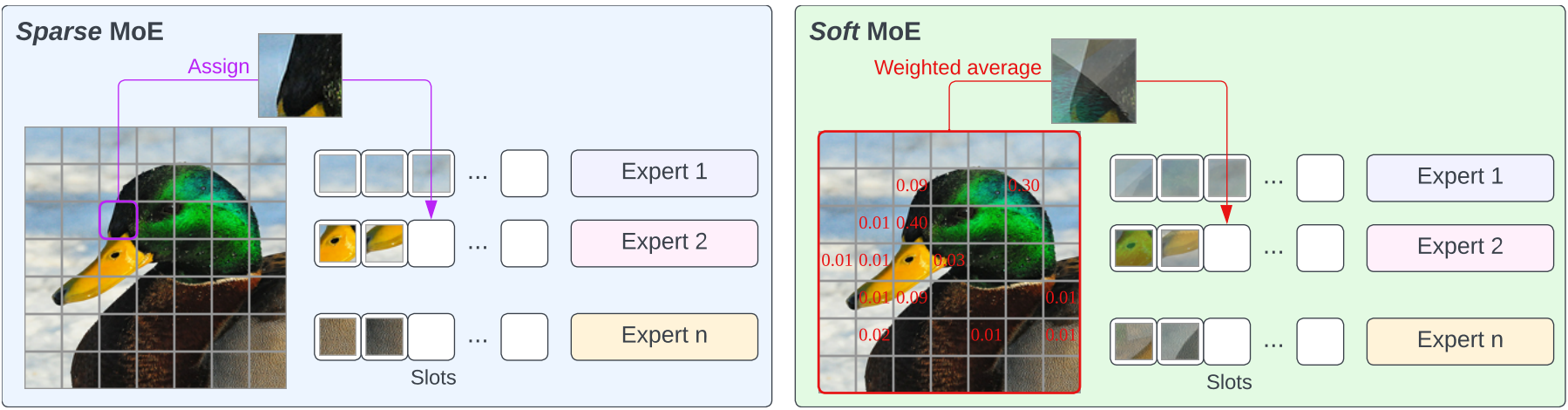
Soft Mixture of Experts
SoftMoE는 단일 토큰이 아닌 토큰들의 가중 평균을 할당한다.
사실 이 그림만 봐도 SoftMoE 완벽 이해됨.
Algorithm description
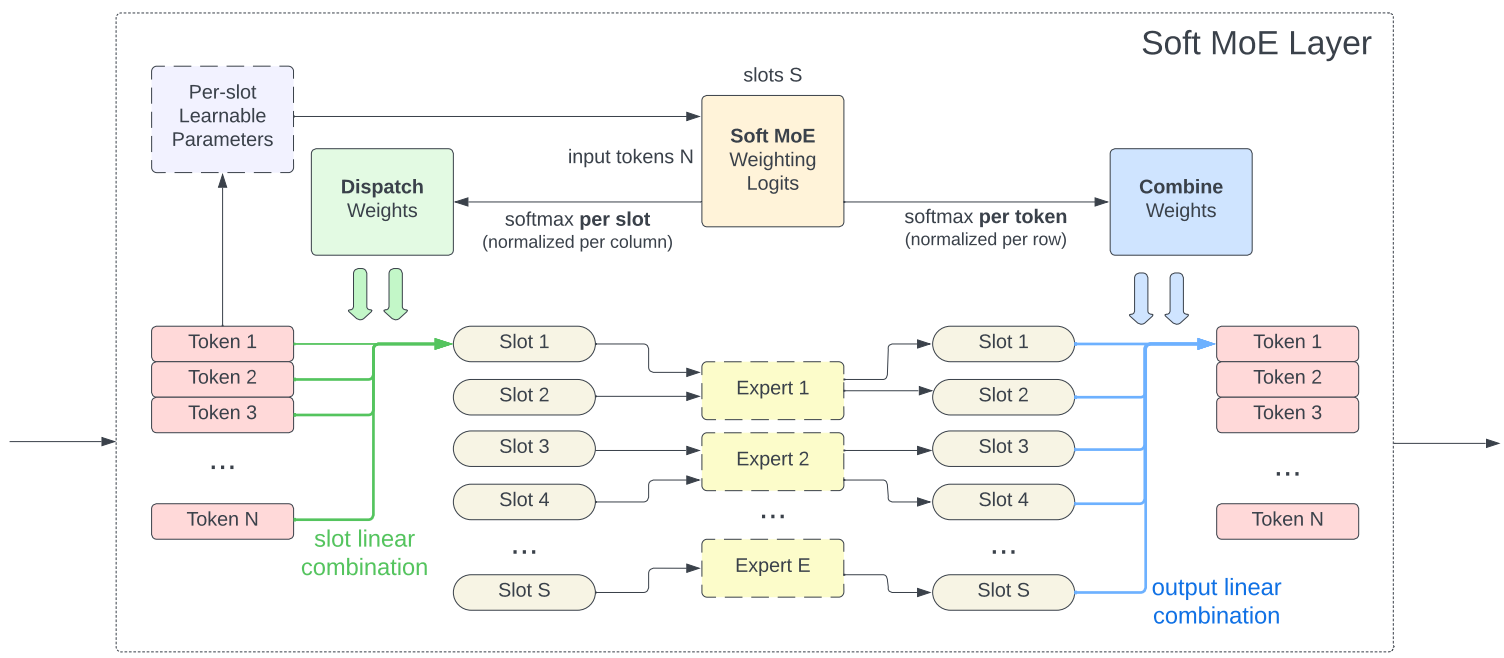
d 차원인 m개의 토큰이 포함된 입력 시퀀스 X, d 차원 피라미터와 p slots을 가진 n개의 전문가가 포함된 MoE layer.
각 슬롯은 개별적으로 피라미터 Φ를 가진다.

Input slots X̃는 다음과 같이 입력 X에 각 슬롯에 대한 피라미터 Φ를 적용하고 softmax를 적용하는 dispatch weight D를 통해 계산된다.

출력은 반대 연산인 combine weight C를 통해 계산됨.

슬롯 수가 SoftMoE의 핵심 하이퍼 피라미터이다.
Properties of Soft MoEs and connections with Sparse MoEs
Fully differentiable
SoftMoE layer의 모든 작업은 연속적이고 완전히 미분 가능.
No token dropping and expert unbalance
각 슬롯이 모든 토큰의 가중 평균으로 채워지기 때문에 token drop, 전문가 불균형 등의 문제를 피한다.
Fast
SoftMoE는 정렬, TopK 같은 하드웨어 가속기에 적합하지 않은 작업을 피하기 때문에 더 빠르다.
Features of both sparse and dense
각 슬롯이 어느 정도 모든 토큰을 반영하기 때문에 sparse와 dense의 속성을 모두 가짐.
Per-sequence determinism
일반적인 MoE는 배치 내에서 라우팅을 수행하기 때문에 배치 수준으로 결정적이지만 SoftMoE는 시퀀스 수준에서 결정적임.
Image Classification Experiments

'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation (0) | 2024.03.14 |
|---|---|
| VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (0) | 2024.03.12 |
| FiT: Flexible Vision Transformer for Diffusion Model (0) | 2024.03.05 |
| EVA-CLIP-18B: Scaling CLIP to 18 Billion Parameters (1) | 2024.02.20 |
| Rethinking Patch Dependence for Masked Autoencoders (CrossMAE) (1) | 2024.01.30 |
| Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data (6) | 2024.01.26 |



