MiDaS + Perturbation이 주입된 대규모 unlabeled data + Semantic feature loss
단순한 Encoder-Decoder 구조로 모든 이미지를 처리하는 depth foundation model
[Github]
[arXiv](2024/01/19 version v1)




Abstract
기술 모듈을 추구하지 않고 어떠한 상황에서도 모든 이미지를 다루는 단순하면서도 강력한 depth foundation model을 구축하는 것을 목표로 한다.
Depth Anything
- Learning Labeled Images
- Unleashing the Power of Unlabeled Images
- Semantic-Assisted Perception

Labeled data Dl로 teacher model T를 학습하고 unlabeled data Du에 depth label 할당 후 두 데이터셋을 통해 student model S 훈련.
Learning Labeled Images
참고: Affine-invariant loss를 통해 다양한 데이터셋에서 혼합 훈련이 가능한 MiDaS
사전 훈련된 DINOv2 인코더 가중치로 초기화하고 MiDaS와 같은 방법으로 훈련한다.
MiDaS에서 제안한 데이터셋에서 저품질 데이터를 제거한 세트를 사용하며 분할 모델을 사용하여 하늘을 감지하고 깊이를 최대로 설정한다.
Unleashing the Power of Unlabeled Images
대규모의 공개된 unlabeled dataset을 사용한다.

Unlabeled data를 T에 입력하여 pseudo labeled set을 얻고
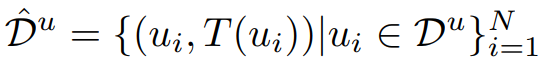
labeled set와 같이 S의 훈련에 사용한다.
하지만 단순히 unlabeled set을 추가하여 훈련했을 때 성능을 향상하지 못했다.
따라서 unlabeled image에 섭동을 추가하여 더 어려운 최적화 목표에서 이미지 표현을 얻도록 강요한다.
- Strong color distortions, including color jittering and Gaussian blurring
- CutMix
먼저 CutMix 수행:


각 마스크에서 S, T, affine-invariant loss를 통해 손실 계산:


S에는 color distortion이 적용된 이미지, T에는 깨끗한 이미지를 입력한다.
Semantic-Assisted Perception
추가적인 semantic 정보를 제공하고 pseudo label의 noise에 대처하기 위해 추가 인코더를 사용하여 보조 손실을 계산한다.
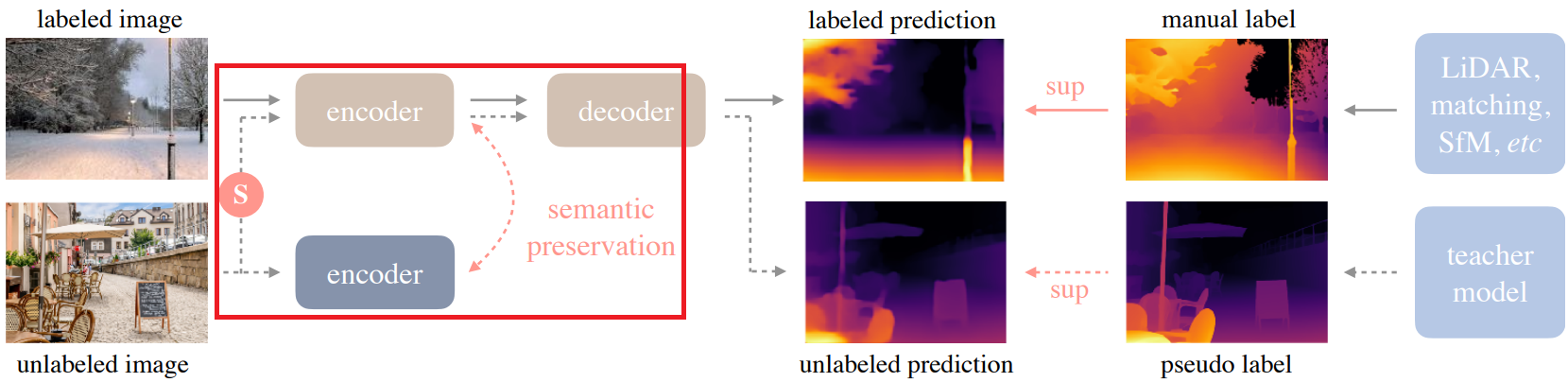
Feature alignment loss:
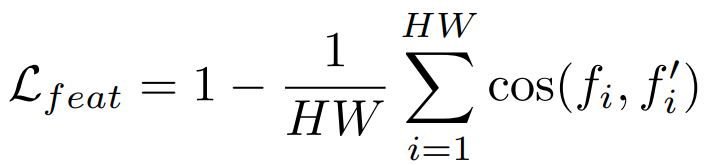
DINOv2의 성능이 강력하기 때문에 fine-tuning 없이 고정된 DINOv2 encoder를 사용했음에도 성능이 크게 향상되었다.
Semantic encoder는 같은 객체의 다른 부분에 대해 유사한 feature를 생성하는 경향이 있다. 하지만 depth space에서는 동일한 객체의 feature 내에서도 서로 다른 깊이를 가질 수 있기 때문에(e.g. 자동차의 전면과 후면) 이는 적절하지 않다.
따라서 허용 오차 α를 설정하여 코사인 유사도가 α를 초과하는 픽셀에서는 Lfeat를 계산하지 않는다.
유의할 점, 지금까지 언급된 데이터 섭동, feature 정렬은 unlabeled data에만 적용된다.
최종 손실은 Ll + Lu + Lfeat의 조합
Experiment
디코더는 DPT decoder를 사용. 무작위로 초기화되기 때문에 인코더에 비해 큰 학습률을 사용한다.
Depth Anything
This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this
depth-anything.github.io
'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| From Sparse to Soft Mixtures of Experts (SoftMoE) (2) | 2024.02.23 |
|---|---|
| EVA-CLIP-18B: Scaling CLIP to 18 Billion Parameters (1) | 2024.02.20 |
| Rethinking Patch Dependence for Masked Autoencoders (CrossMAE) (1) | 2024.01.30 |
| Scalable Pre-training of Large Autoregressive Image Models (AIM) (0) | 2024.01.19 |
| PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models (0) | 2024.01.17 |
| Denoising Vision Transformers (DVT) (0) | 2024.01.10 |



