[Github]
[arXiv](2024/03/01 version v1)

Abstract
피라미드 형태의 LLaMA-like vision transformer를 통한 이미지 모델링
Method
Plain Transformer
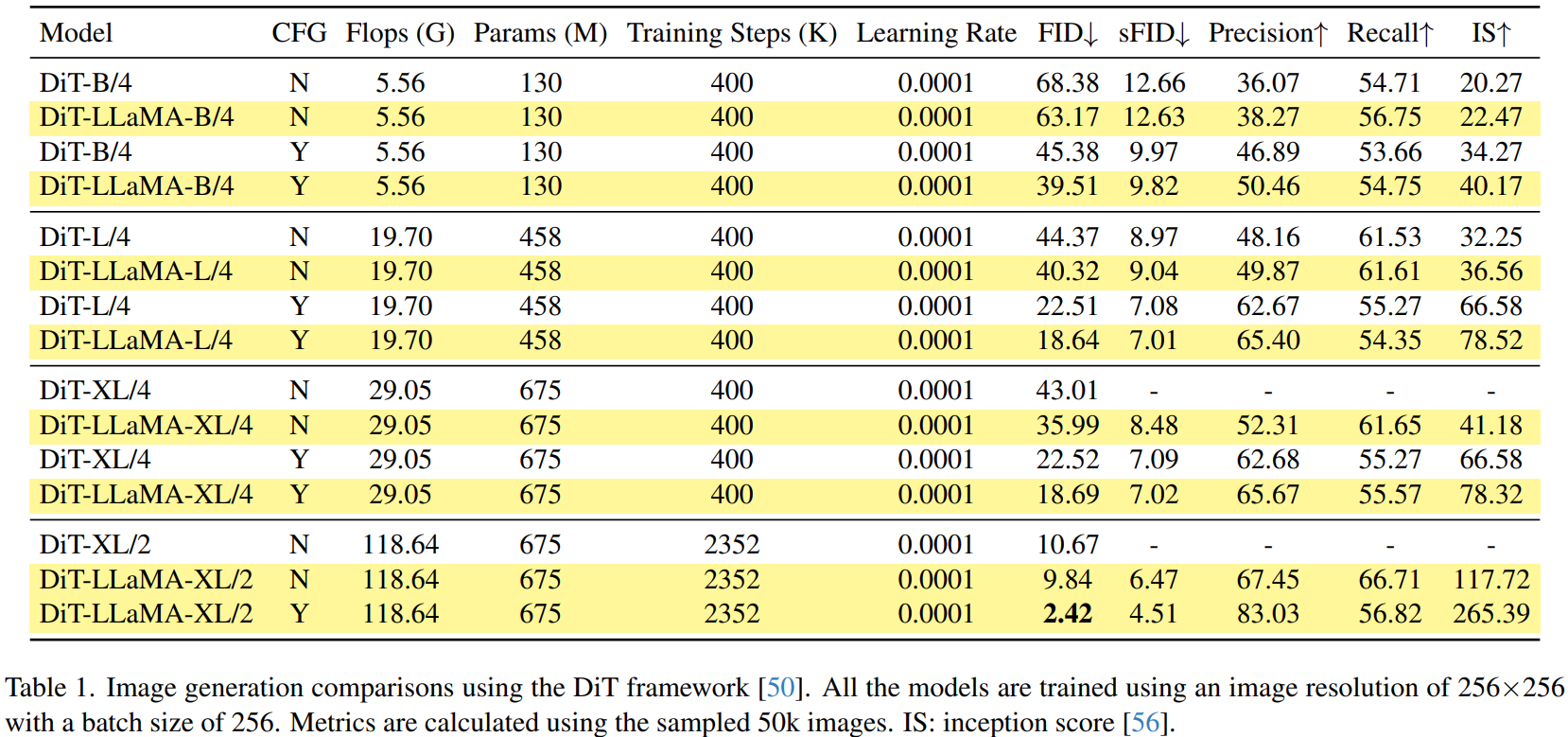
DiT framework를 기반으로 하며, Stable Diffusion의 사전 훈련된 VAE를 사용했다.
LLaMA를 따라 일반 ViT에서 RoPE, SwiGLU 채택.
실험적으로 LayerNorm이 RMSNorm보다 좋았으므로 변경하지 않았다.
패치의 행, 열에 각각 RoPE를 적용하는 2D RoPE를 사용하였다.

Pyramid Transformer
Self-attention의 효율성을 위해 피라미드 구조를 사용하며, Swin 보다 강력한 Twins의 구조를 채택하였다. (b)
Training or Inference Beyond the Sequence Length
2D RoPE + 위치 보간을 사용하면 훈련 해상도 이상의 이미지를 생성할 수 있다. (FiT)
RoPE는 목표 해상도에 따라 자동으로 조정되며 본문에서 이를 AS2DRoPE (auto-scaled 2D RoPE) 라고 부른다.
Twins의 GSA의 경우 대표자의 위치 정보는 커널의 중간(위치의 평균)이다.

Experiments