[Github]
[arXiv](2024/02/19 version v1)

Abstract
RoPE의 context 확장을 이미지에 적용해 무제한의 해상도와 종횡비의 이미지를 생성할 수 있는 Flexible Vision Transformer (FiT) 제안
Flexible Vision Transformer for Diffusion
Preliminary
본문의 Preliminary 부분은 LongRoPE 논문 리뷰의 Preliminary에 더 자세히 설명되어 있슴다.
1-D RoPE
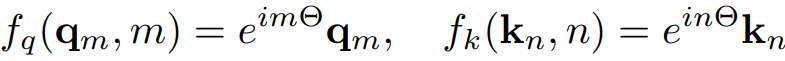

NTK-aware Interpolation
Scale factor s를 통해 회전 주파수를 축소하여 fine-tuning 없이 context 길이를 확장한다.

YaRN (Yet another RoPE extensioN) Interpolation
차원 d에 따라 회전 주파수를 각각 다르게 조정한다.


또한 RoPE scaling term을 추가한다.
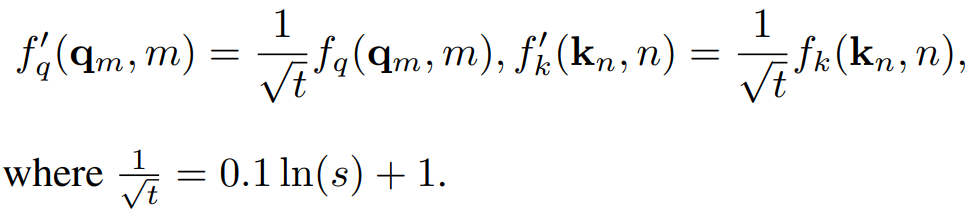
Flexible Training and Inference Pipeline
FiT는 DiT 기반 모델이다. DiT와 달리 이미지를 고정 해상도로 조정하거나 자르지 않고 최대 해상도 제한(HW ⩽ 2562)으로만 조정한다.
입력 이미지를 사전 훈련된 VAE로 인코딩하고 패치화하여 시퀀스를 얻는다. 모든 시퀀스 길이는 Lmax로 고정이고 남는 부분은 패딩으로 채운다.
추론 시에는 조건에 따라 위치 맵을 정의하고 denoising을 수행.
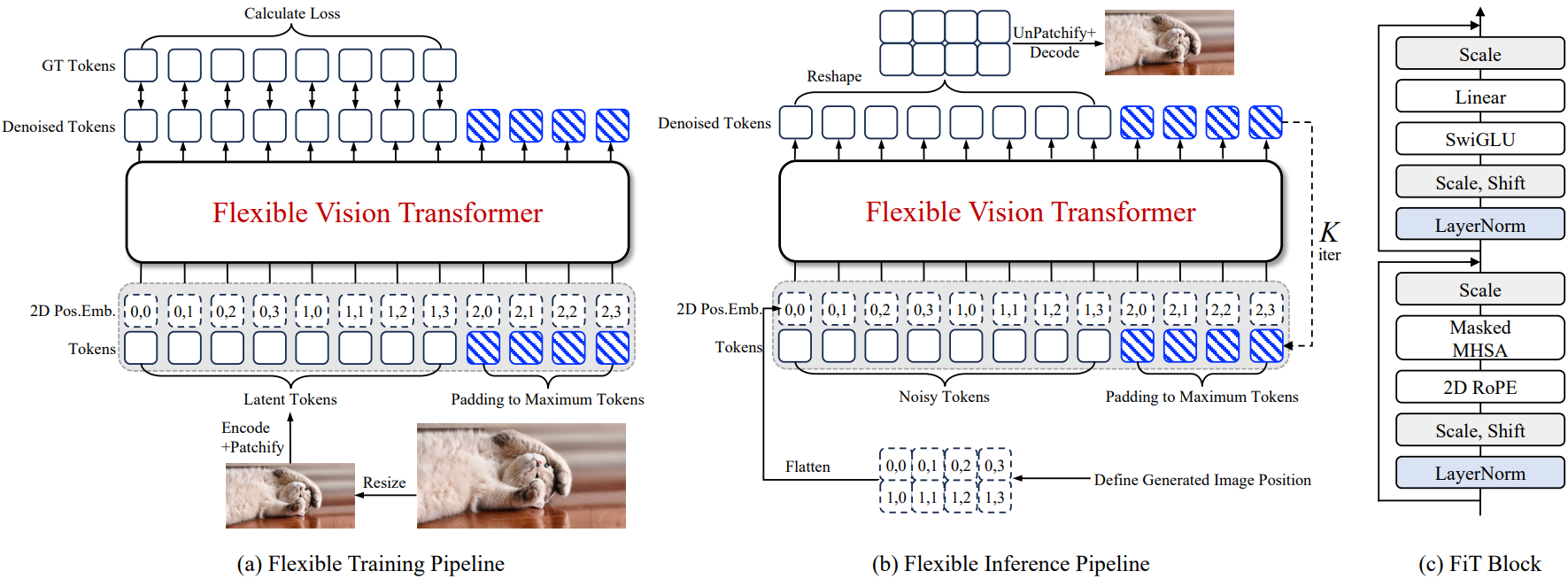
Flexible Vision Transformer Architecture
아키텍처 수정사항
Replacing MHSA with Masked MHSA
패딩 토큰과의 attention을 피하기 위해 -inf mask 사용.
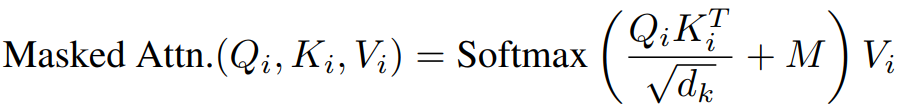
Replacing Absolute PE with 2D RoPE
각 query, key 벡터에 높이, 너비에 대한 RoPE를 별도로 적용하고 concat 한다.


Replacing MLP with SwiGLU
FFN layer의 MLP를 SwiGLU로 대체한다.
Training Free Resolution Extrapolation
높이, 너비에 대한 scaling factor s:


VisionNTK, VisionYaRN을 통해 fine-tuning 없이도 훈련 해상도 이상의 이미지를 생성할 수 있다.
VisionNTK
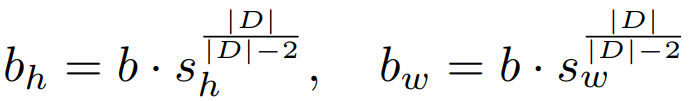
VisionYaRN

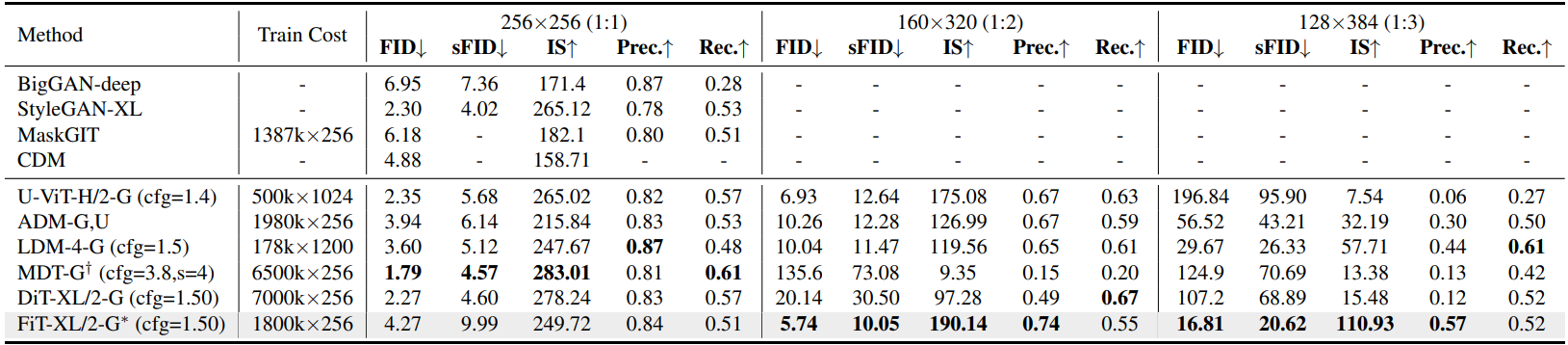
Experiments